import pandas as pd
import tools as ds
from IPython.display import ImageData Sample¶
crashes_initial = pd.read_csv('data/Crashes.csv')
crashes_initial.head()Data Preprocessing¶
There are 80 columns describing a bike crash instance, with many containing code words that are interpreted here: https://pandas team, 2023 and numpy Harris & others, 2020
EDA : Visualizing Bike Collision Trends¶
In our analysis, we aim to identify general trends across bike collisions, spanning temporal and categorical conditions. In these visuals we explore the impact of the pandemic, time of year, time of day, and several road and accident conditions that are associated with our data’s bike crashes.
The onset of the pandemic is associated with a significant drop in bike collisions, very likely due to the fact that there was a general drop in people riding bikes in places or times that were higher risk of getting into a collision. We speculate that a number of factors contributed to the decrease in high-risk bike use from the pandemic, such as the initial quarantine, the residual hybrid or remote work, and general changes in transportation habits. Despite the pandemic conditions improving by 2023, we still a slow inertia in returning to pre-pandemic biking conditions, as seen below:
Image(filename = "figures/Collisions_by_year.png")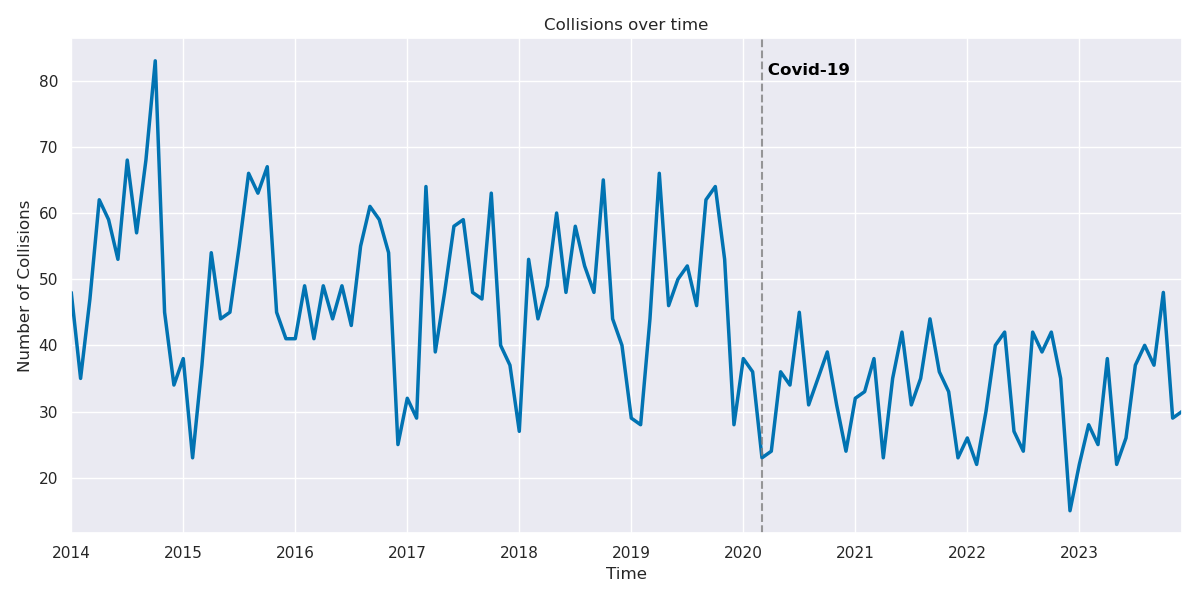
Looking at collisions by month, we see a general trend of less commuters during the winter months of December, January, and February. Brr!
Image(filename = "figures/Collisions_by_month.png")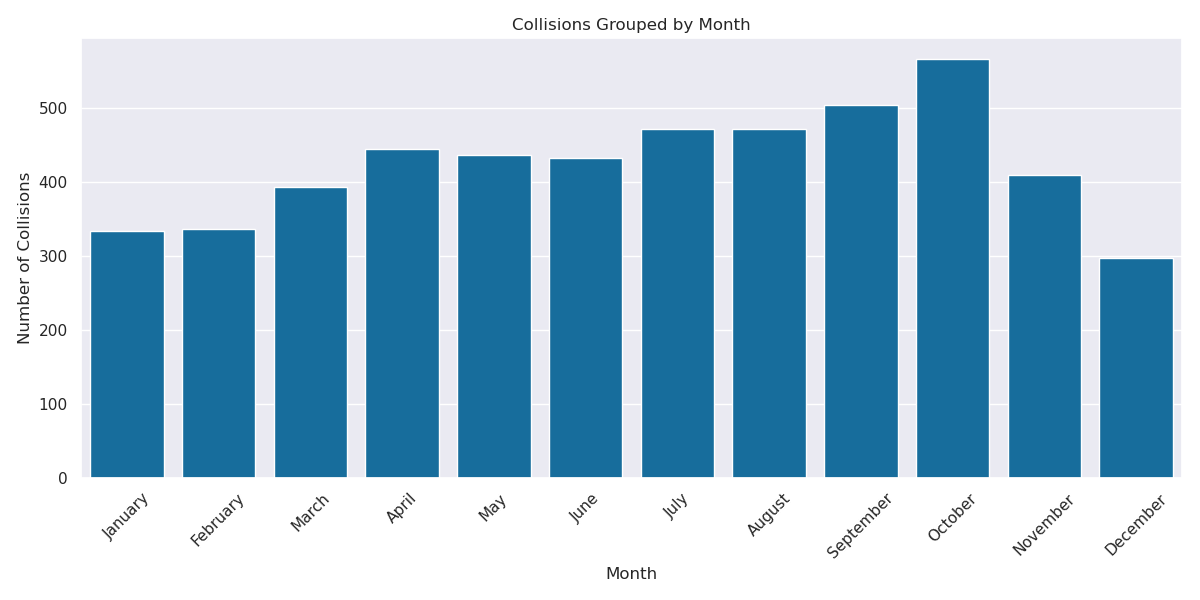
As shown in the figure below, there are no very obvious differences across seasons, in terms of categorical condition variation. However, there is certainly a marked differences in the number of crashes per season, with Winter having the lowest and Fall having the highest (cumulatively). We also note that Fall and Winter have more crashes in the dark, likely due to shorter days but unchanging work hours.
Image(filename = "figures/Collisions_Categories_by_Season.png")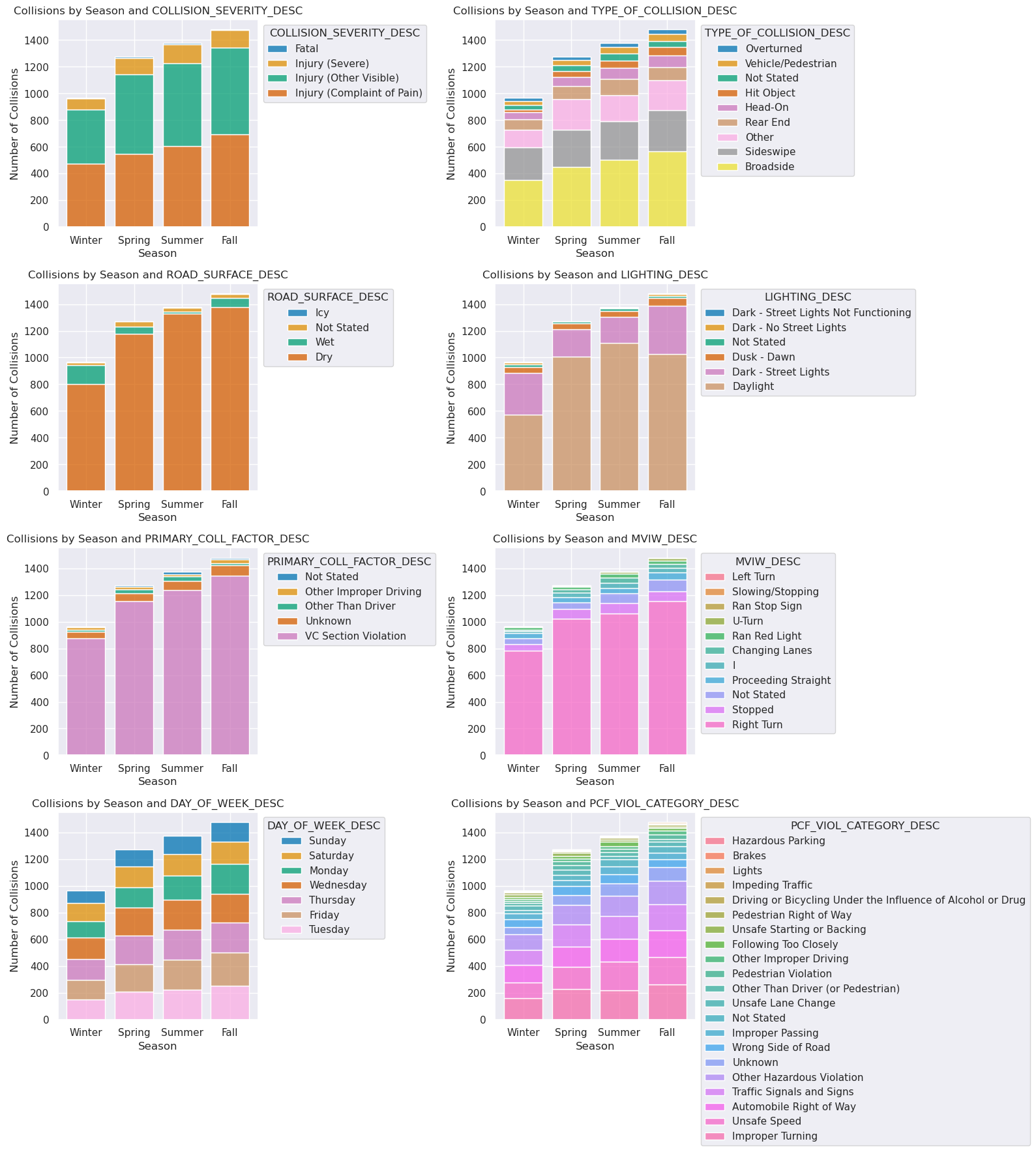
We conducted the same categorical tests, but across days of the week. We see a noteable difference between the typical Monday - Friday work week with lower collision counts for the typical Saturday and Sunday weekend. ‘Recreational’ biking, we infer, is less of a contributor to SF’s bike collisions as compared to commuting bike accidents, where bikers are commuting in the morning alongside cars and busses.
Image(filename = "figures/Collisions_Conditions_by_Day.png")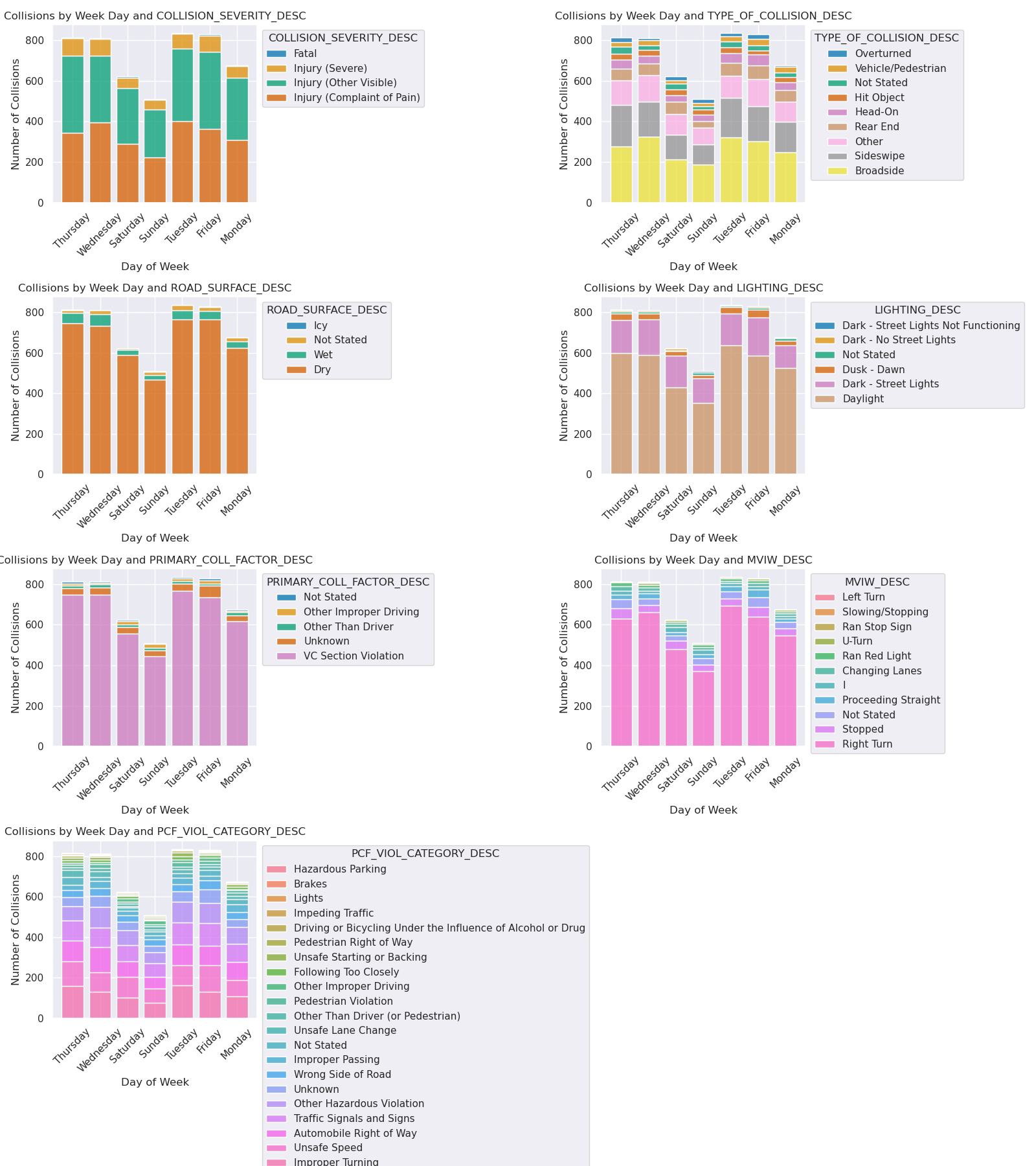
Next we explore the time of day and how that correlates with bike crashes. In the graphs below we observe that weekday crashes are markedly near morning and evening commute time of the 9-5 workday, while weekends follow a more normal distribution. The overwhelming majority of weekday crashes mean that the cumulative collision by time of day graph follows most closely with the weekday trends.
Image(filename = "figures/Collisions_by_TOD.png")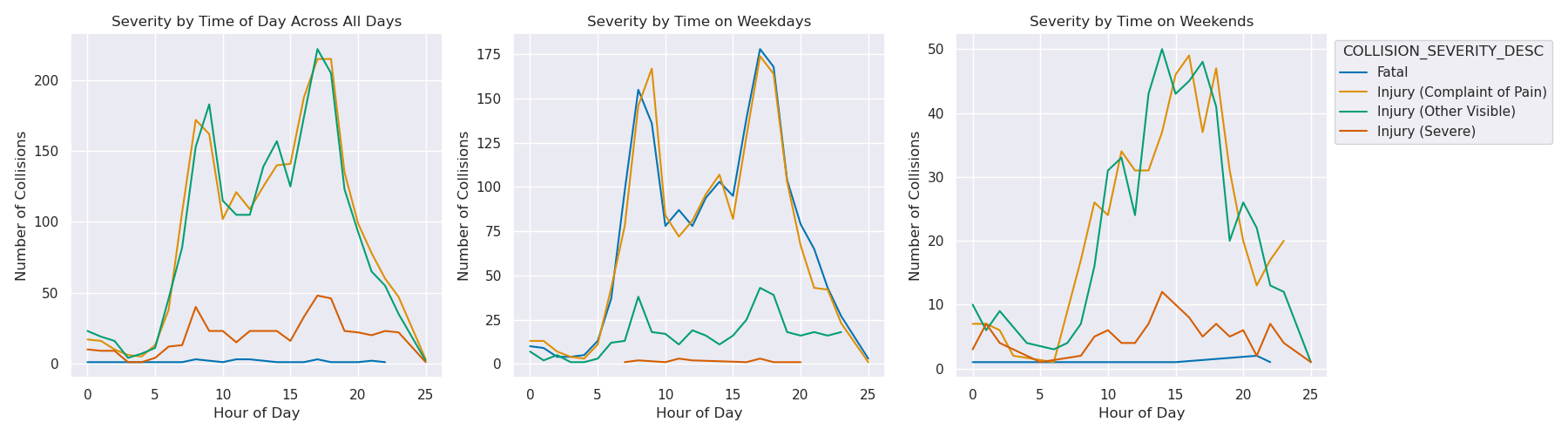
Image(filename = "figures/Crash_Heatmap.png")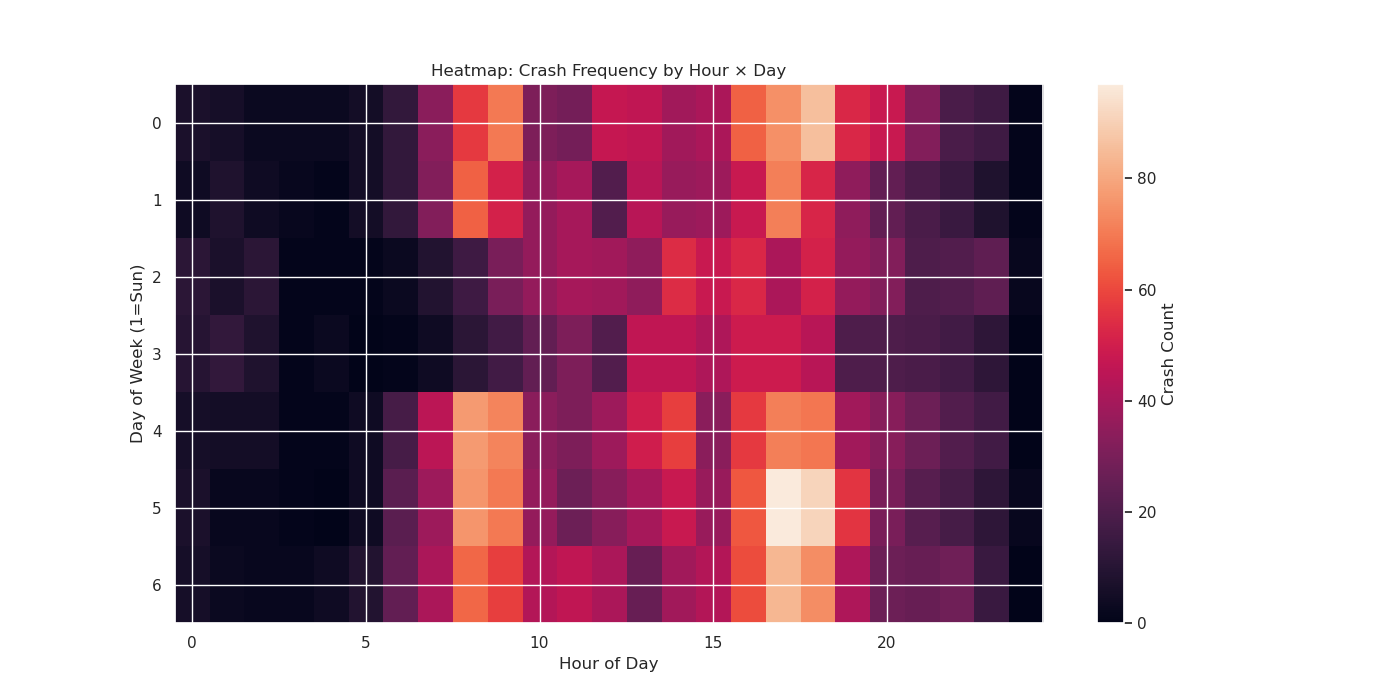
Severe Crashes¶
The focal point of our research question is to understand the conditions that are present in the case of severe or fatal crashes. In the data visualizations below, we find a number of insights. Thankfully, the share of fatalities and severe injuries from bike crashes are extremely low compared to minor injuries. When looking at severity proportions by collision factors, a few things come to light. BUI’s (Biking Under the Influence), biking on the wrong side of road, brake malfunctions, conditions other outside of the biker’s control seem to have higher proportions of crash severity.
Image(filename = "figures/Distr_Collision_Severity.png")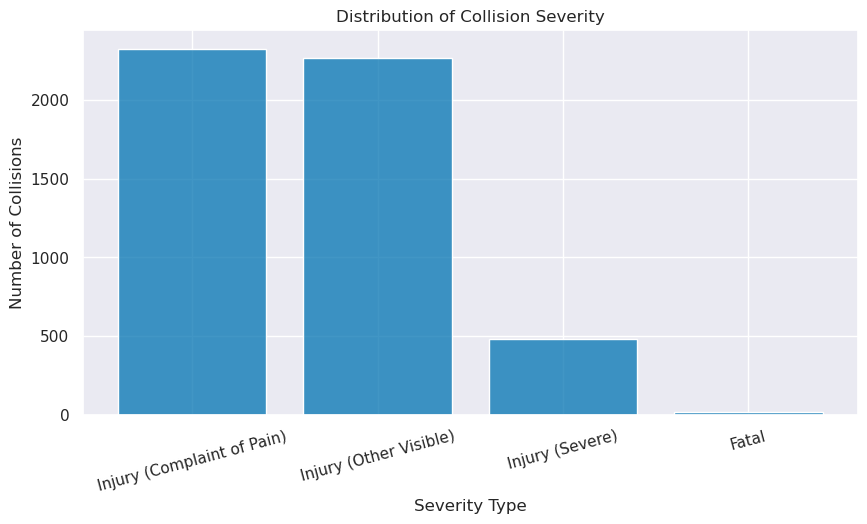
Image(filename = "figures/Fatalities_by_year.png")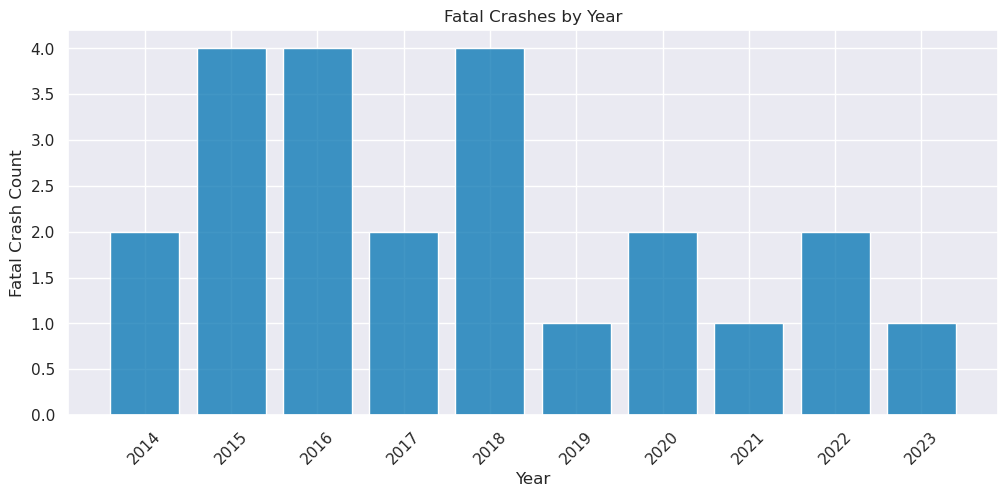
Image(filename = "figures/Collis_Factor_Proportions.png")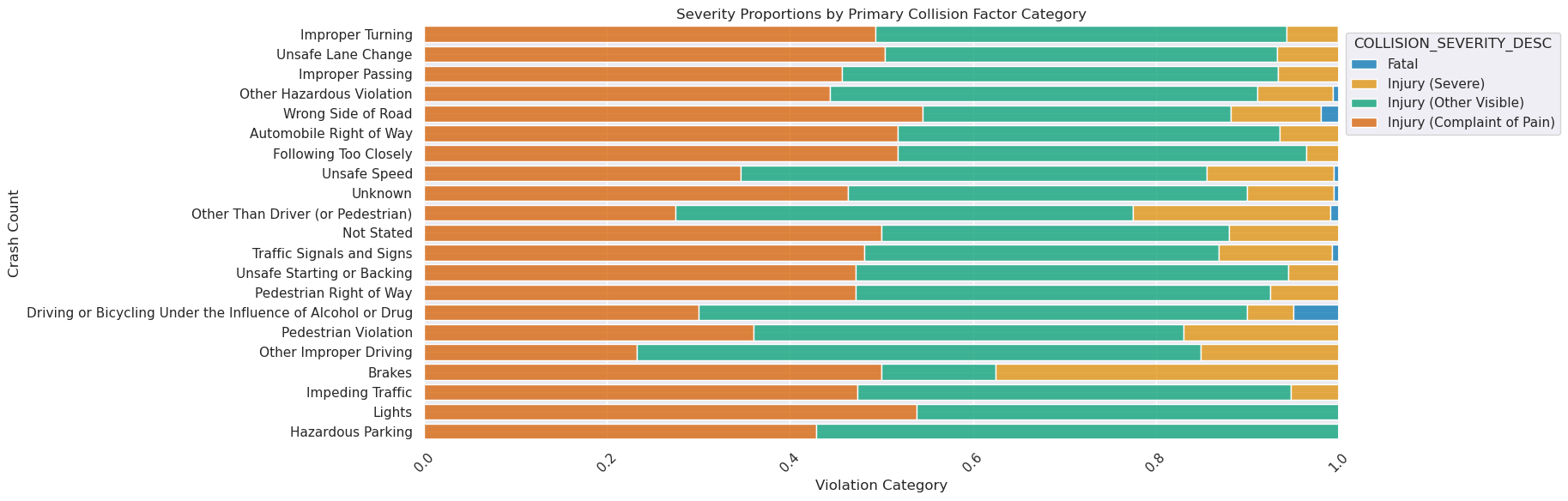
Image(filename = "figures/Severe_Conditions.png")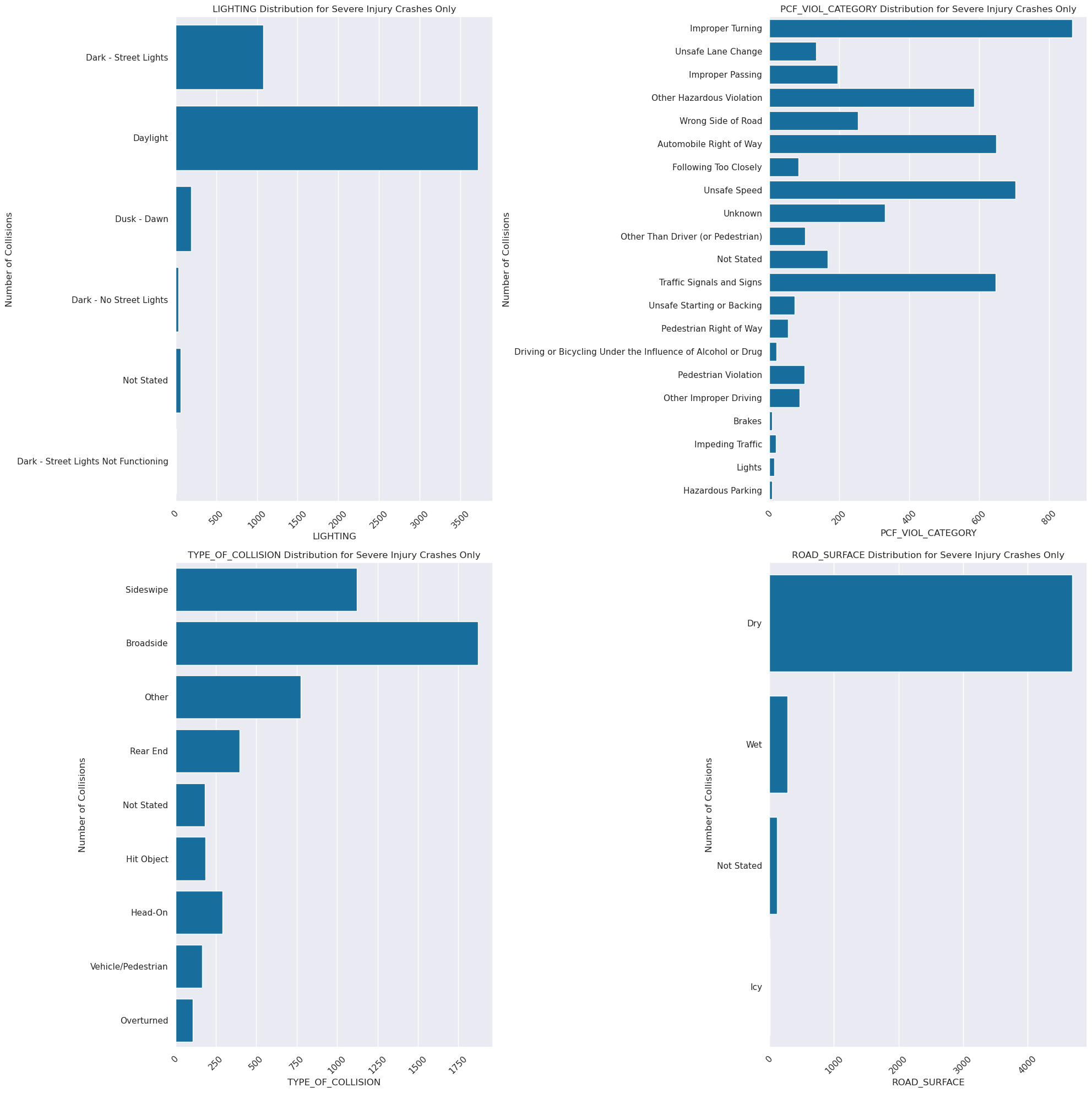
Where do Severe Crashes Happen Often?¶
This section will use the Kernel Density Estimation (KDE) Silverman, 1986 and DBSCAN Clustering methods Ester et al., 1996 to identify locations in San Francisco (SF) that see the highest amount of bike crashes. The KDE method combined with GeoPandas Jordahl & others, 2023 will help visualize crash hotspots around SF. This analysis will continue with all severity of crashes to see if there are locations with greater severities than others.
It is important to note that it may be expected that more crashes will occur in locations where there is more bike/vehicle traffic. However, the infrastructure of the road should match the volume. Therefore, if a high-volume street is showing multiple crashes, that indicates that existing infrasturcture does not support the expected interactions, and infrastructure change would still be needed to address the higher crash occurances.
Crash Severity¶
The following figures show the following:
All crashes for all years
Fatal Crashes
Crashes with Severe Injury
Crashes with Visible Injury
Crashes where there is a Complaint of Pain
Image(filename = "figures/crash_clusters_All_Severities_and_Years.png")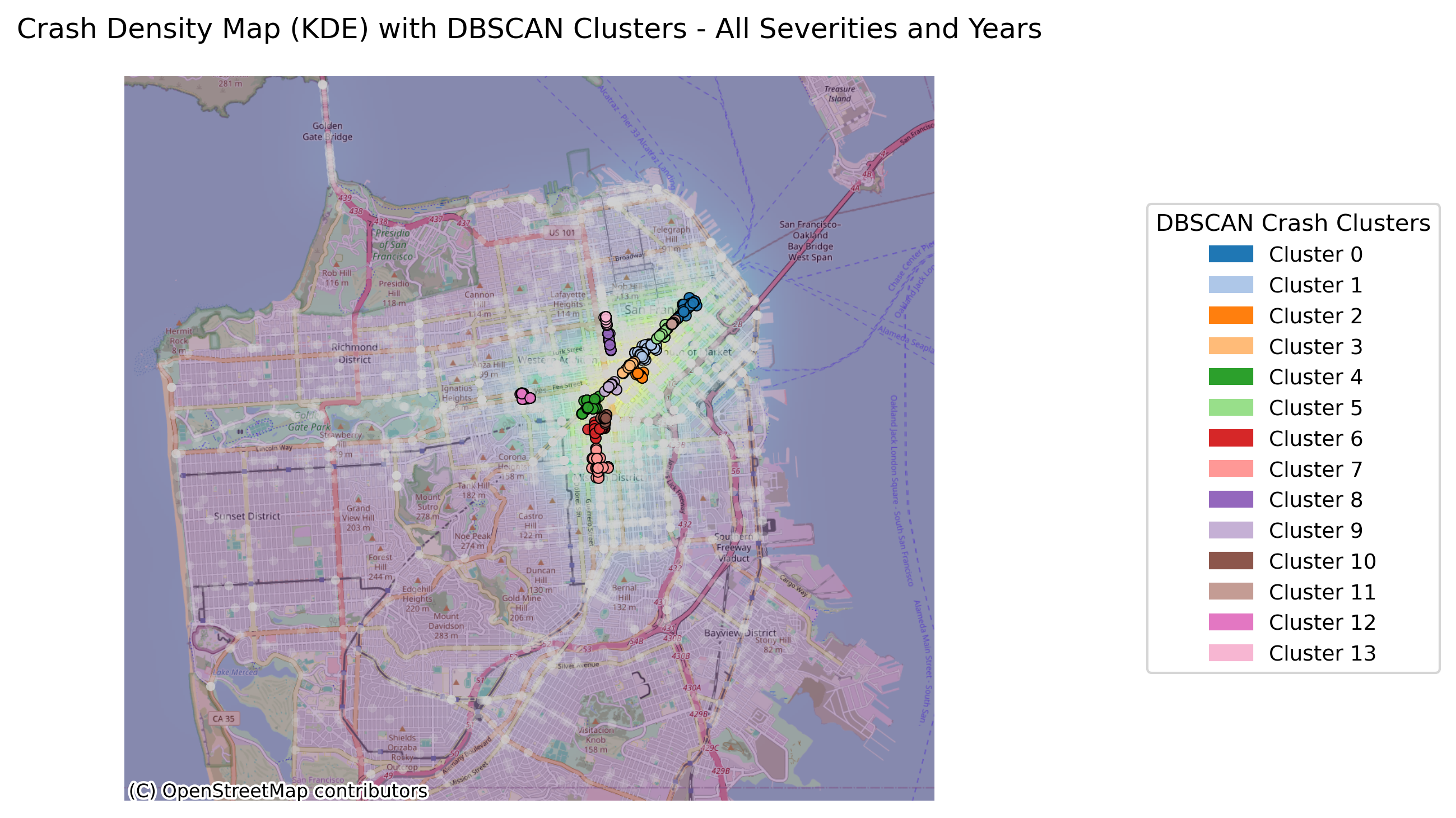
Image(filename = "figures/top_roads_All_Severities_and_Years.png")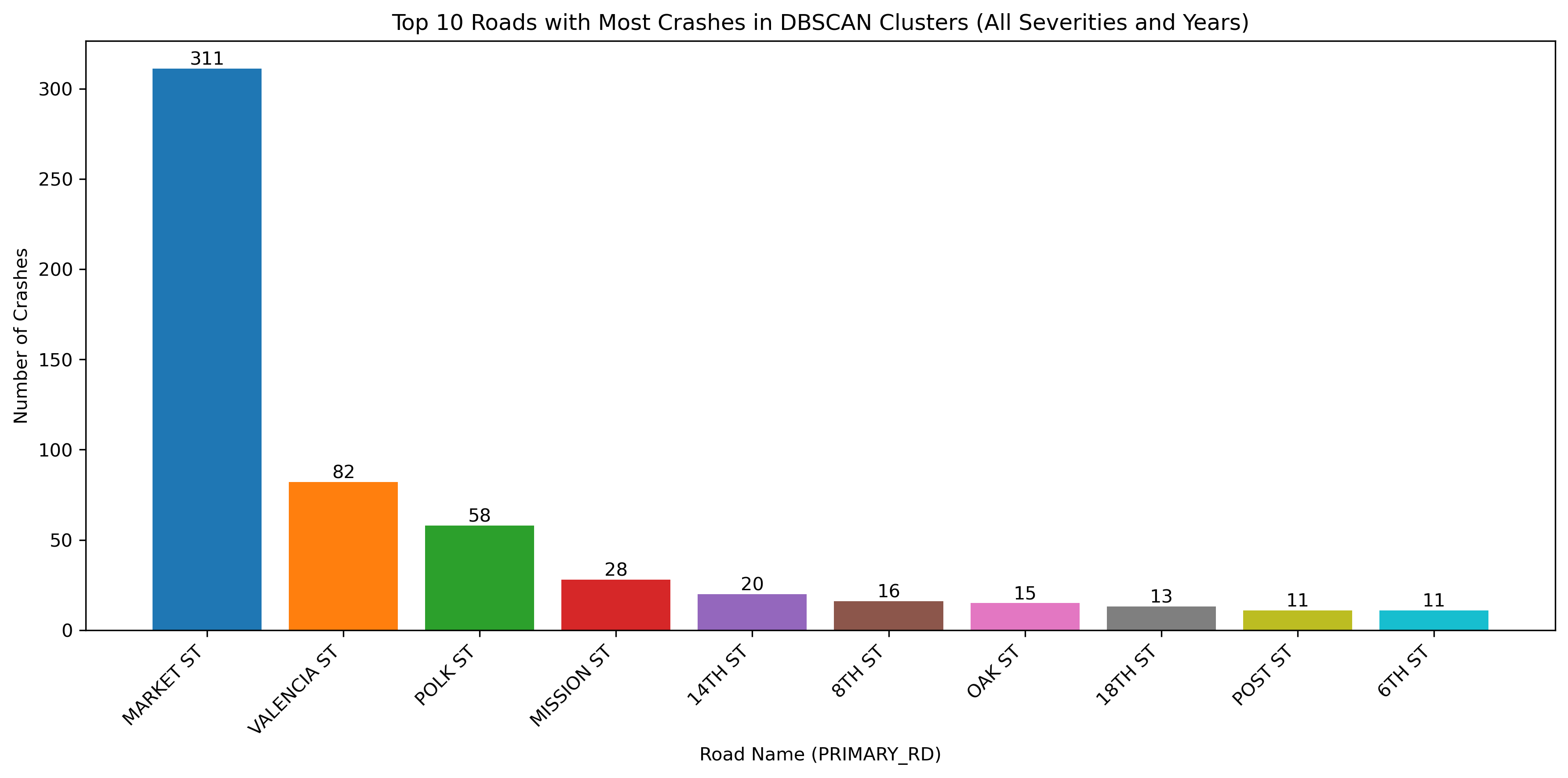
The figure above illustrates all bicycle crashes available in the TIMS data set that occured between 2014 and 2024. The first map shows that the highest density of crashes has occured in the downtown area of SF and the following bar graph indicates that there have been many crashes specifically on Market Street, which is corroborated by the map.
Now, lets break down these crashes by severity. Where do the most severe crashes occur? Is there another trend we can find?
Image(filename = "figures/crash_clusters_Fatal_Crashes,_All_Years.png")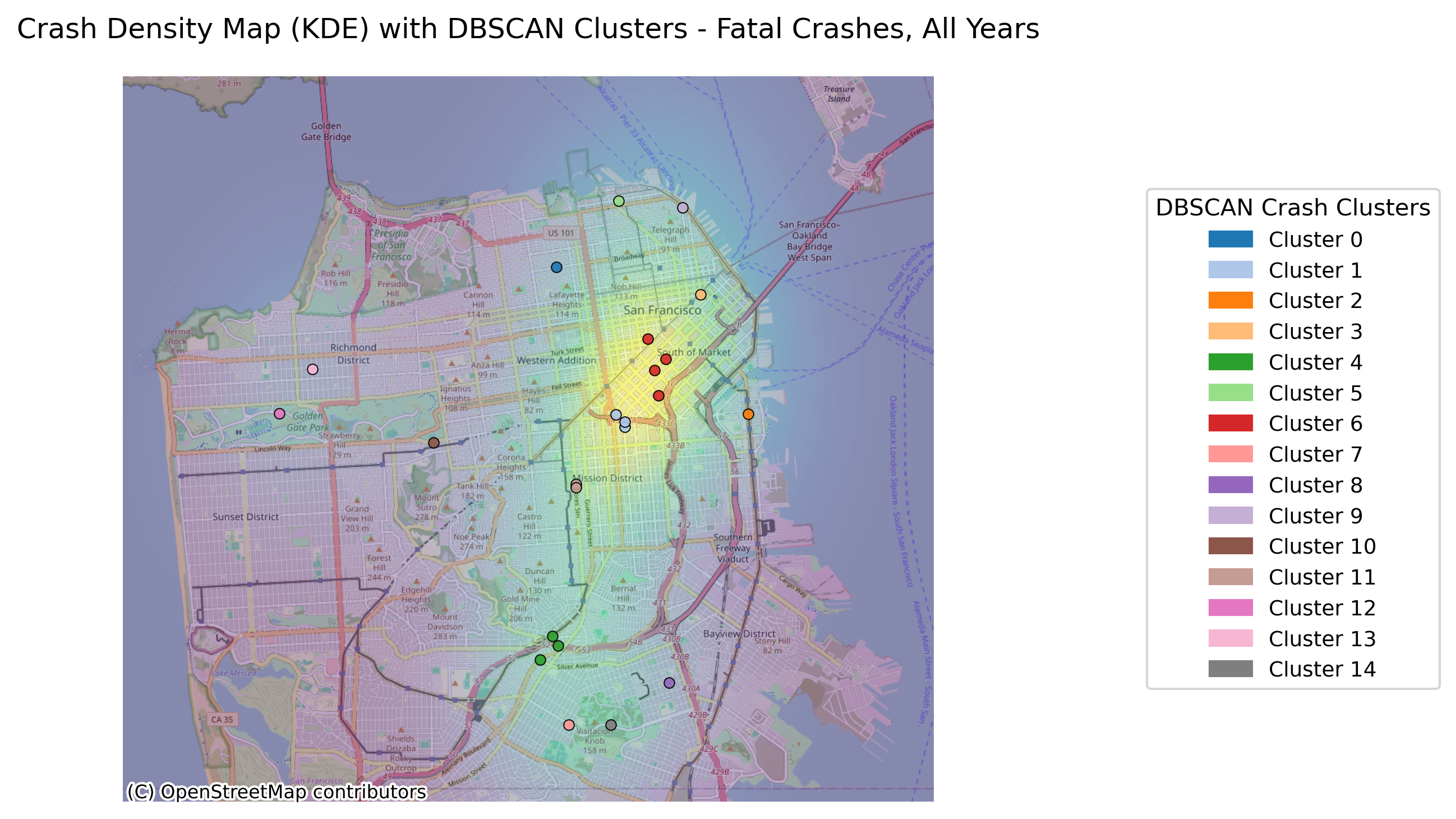
Image(filename = "figures/top_roads_Fatal_Crashes,_All_Years.png")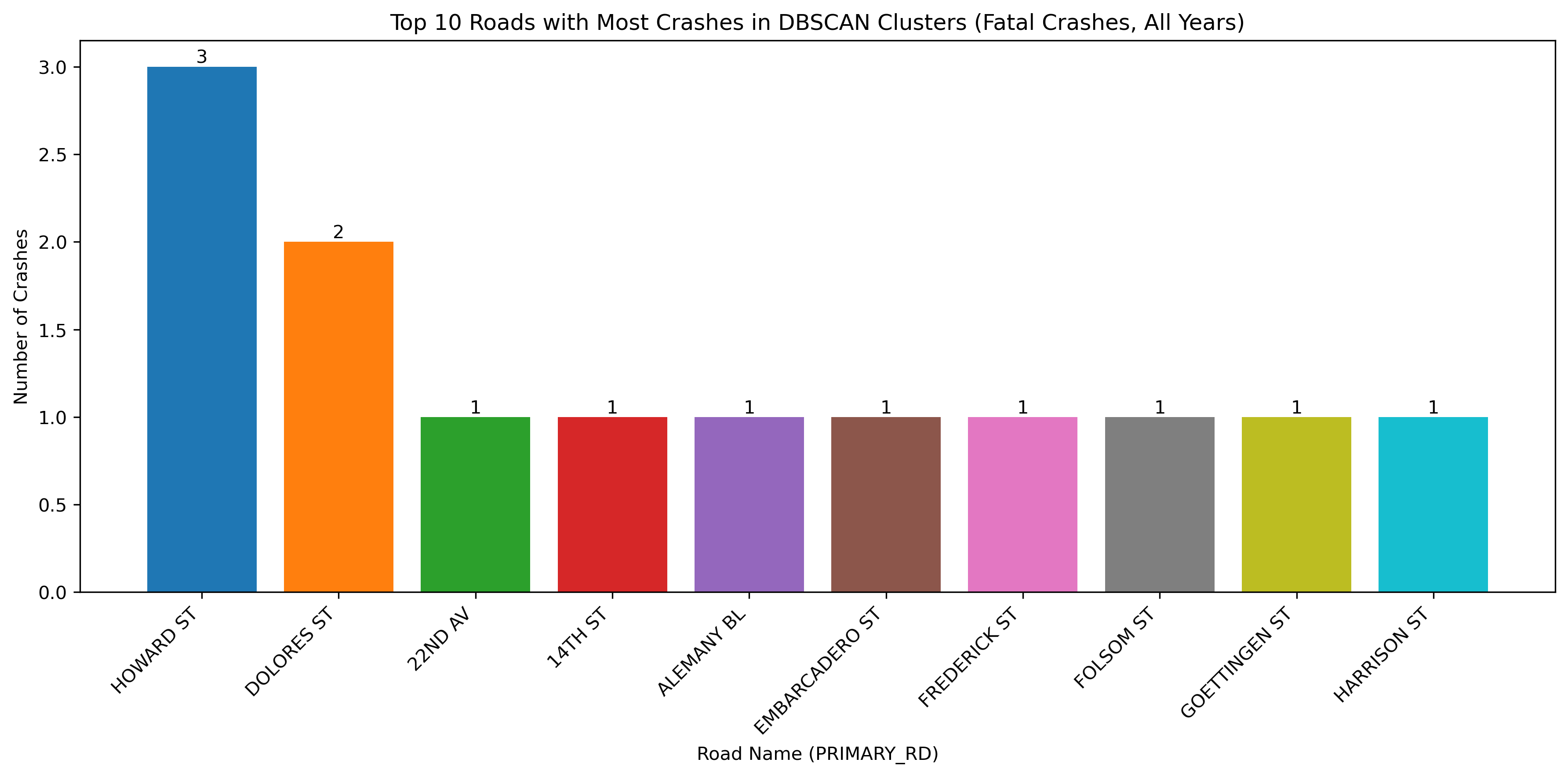
Because there are so few fatal crashes, the minimum number of clusters for the analysis was set to 1 in order to visualize where the fatal crashes occured.
Image(filename = "figures/crash_clusters_Severe_Crashes,_All_Years.png")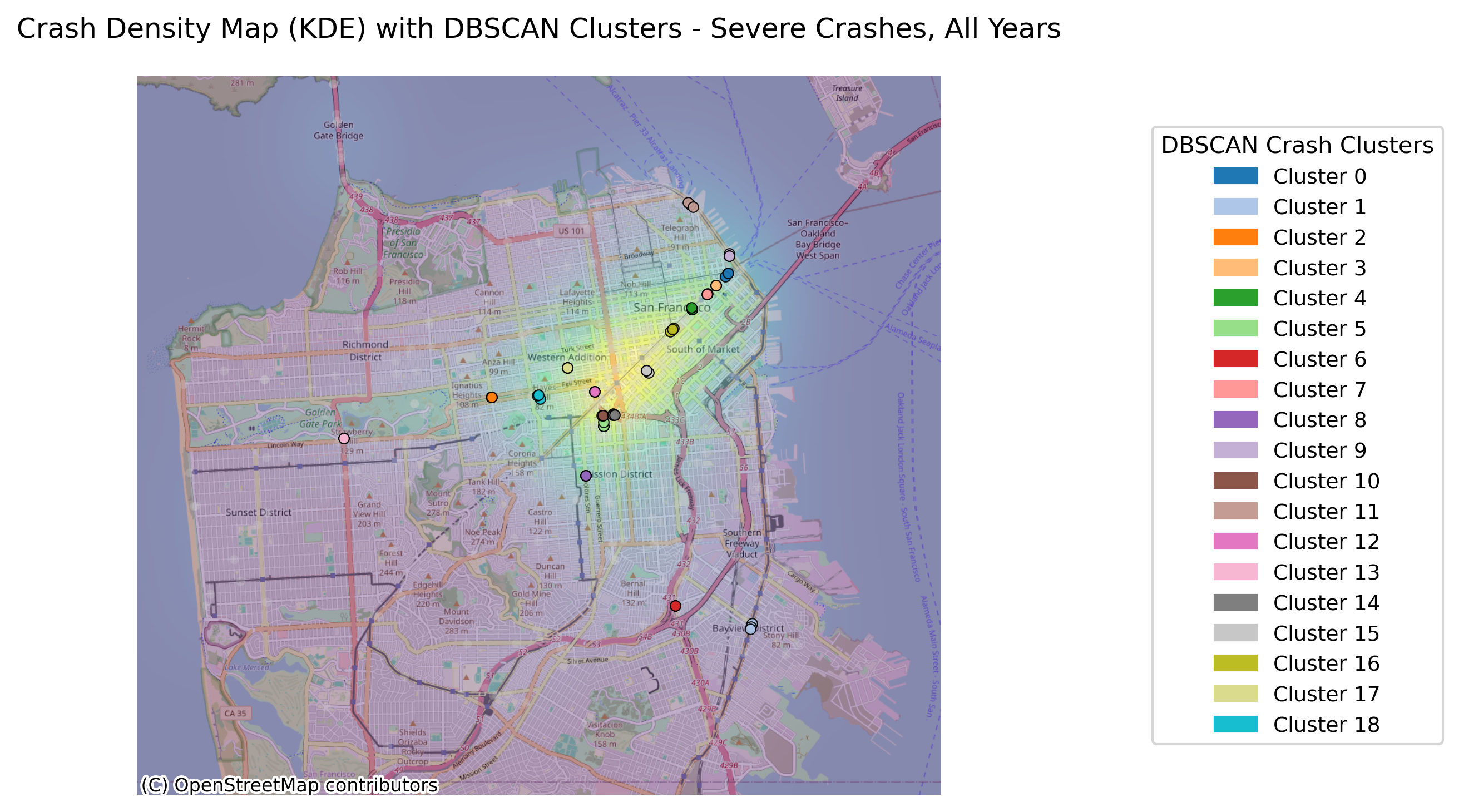
Image(filename = "figures/top_roads_Severe_Crashes,_All_Years.png")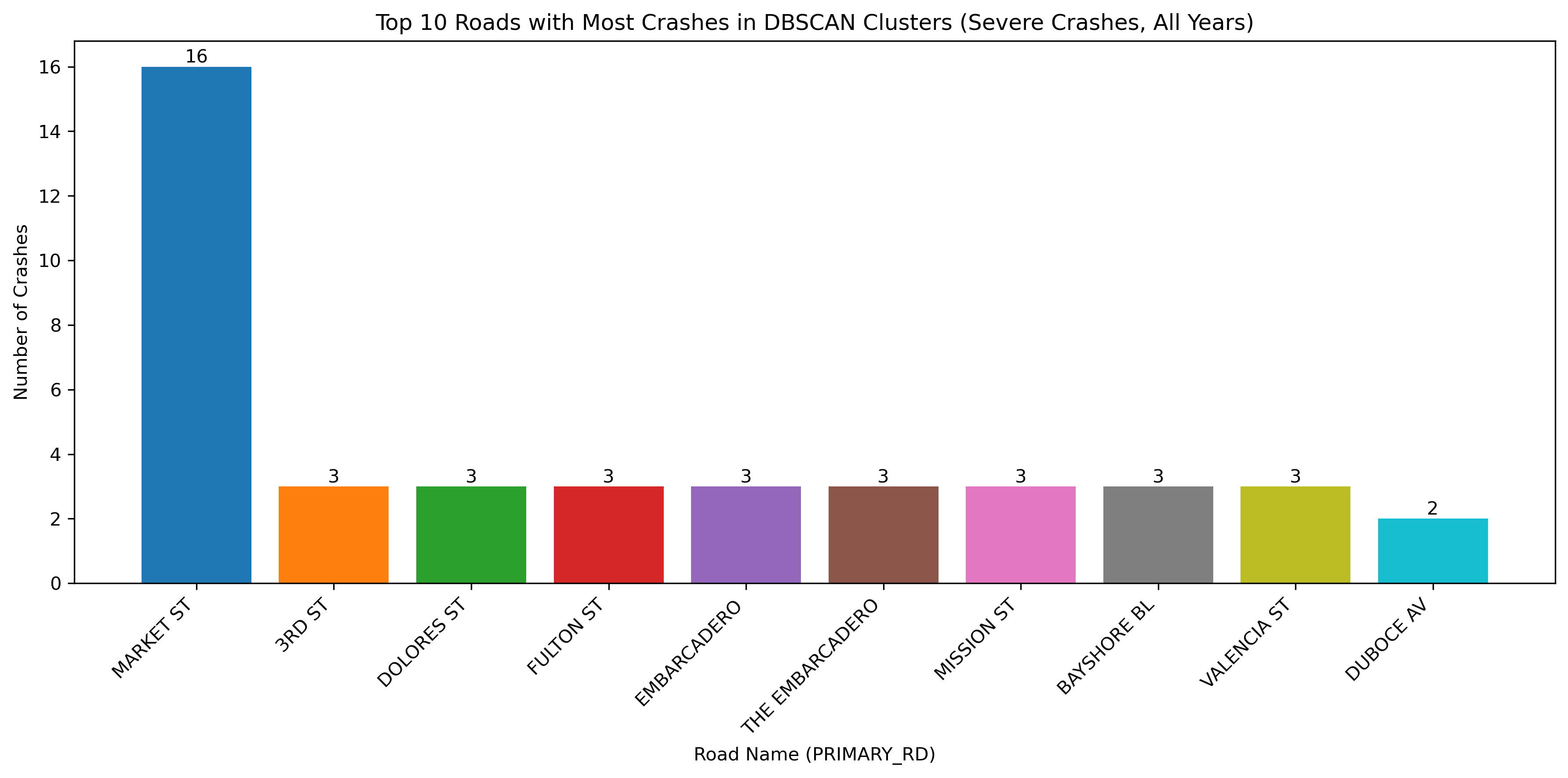
Image(filename = "figures/crash_clusters_Visible_Injury_Crashes,_All_Years.png")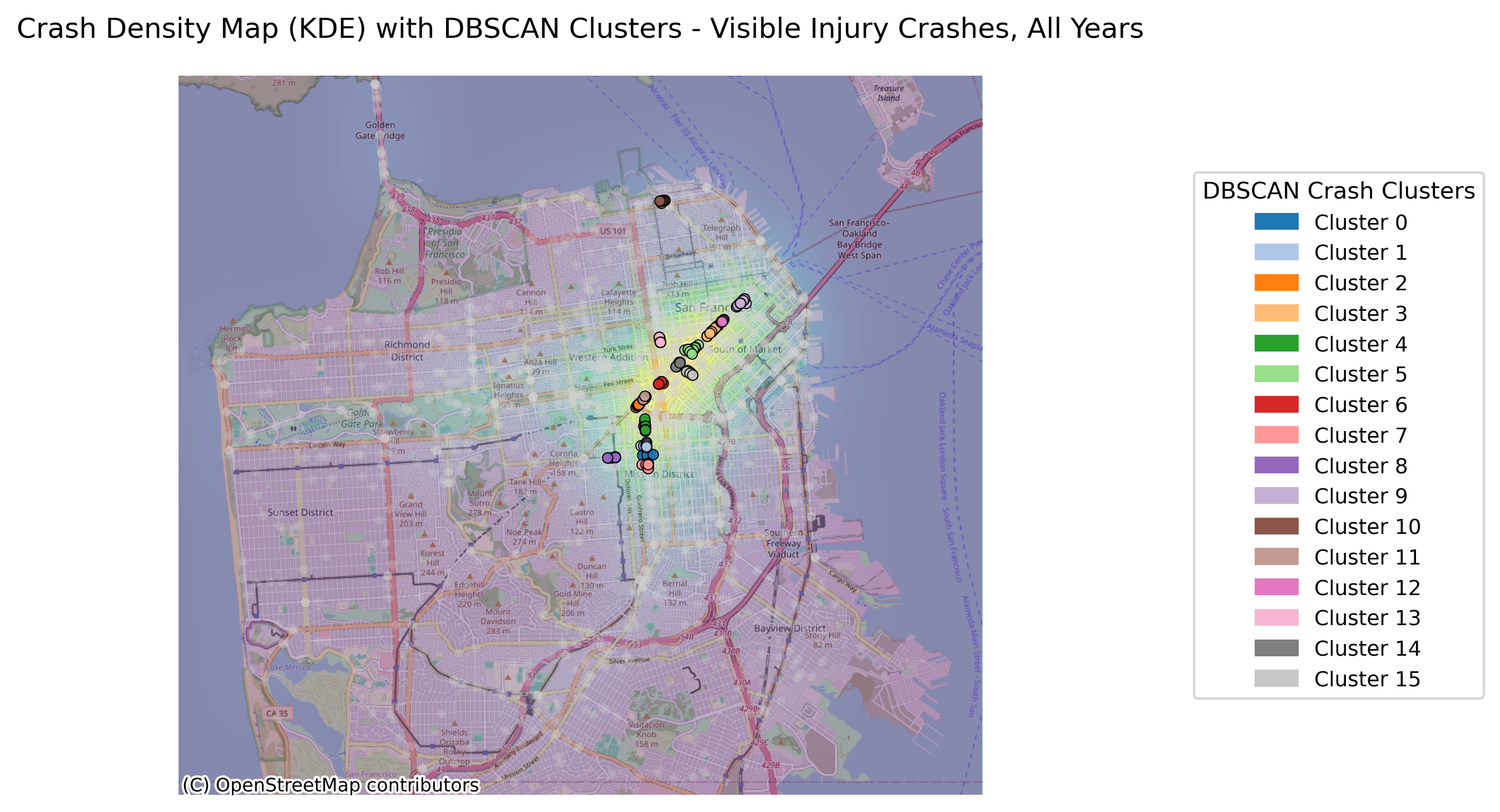
Image(filename = "figures/top_roads_Visible_Injury_Crashes,_All_Years.png")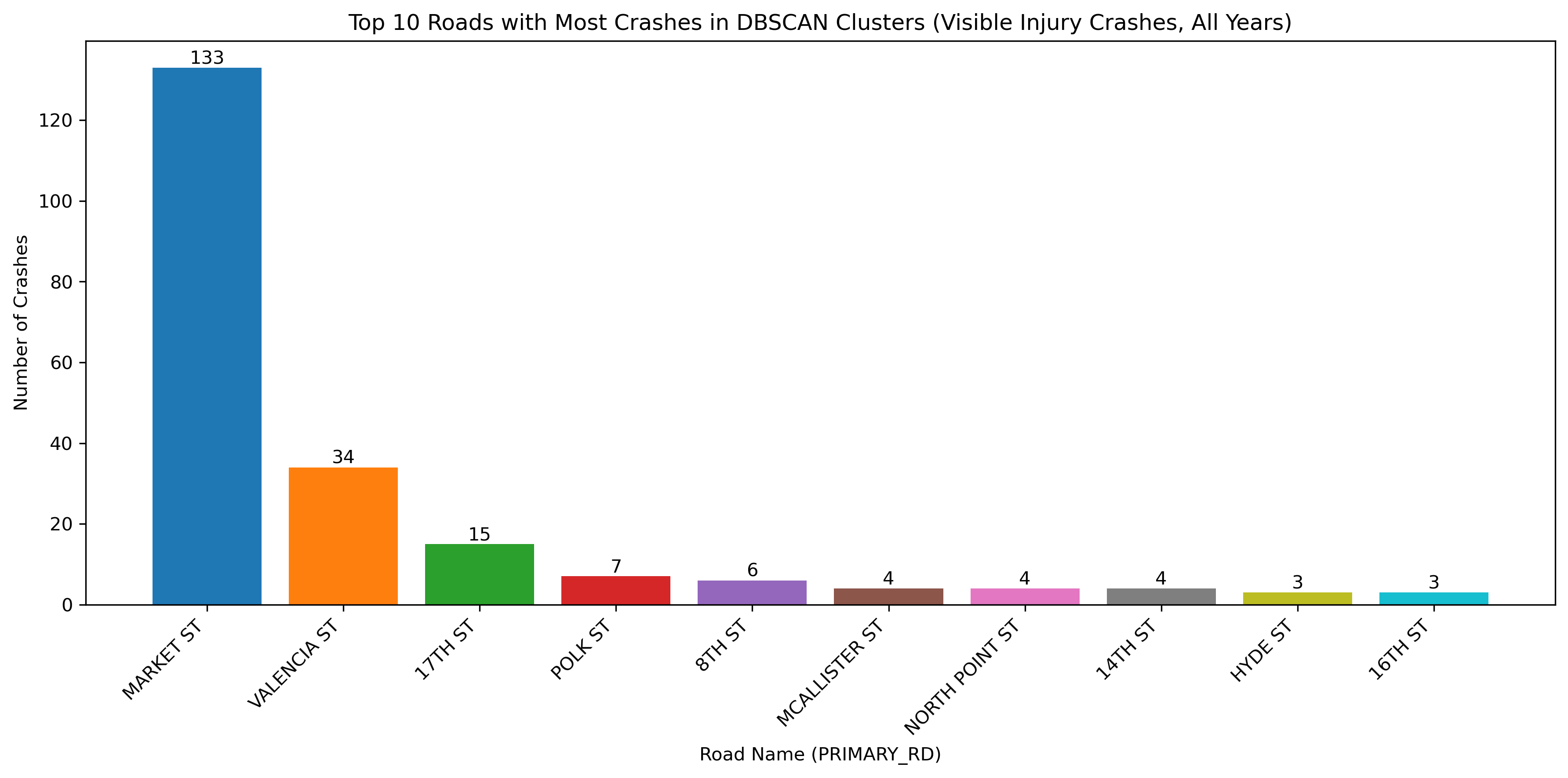
Image(filename = "figures/crash_clusters_Complaint_of_Pain_Crashes,_All_Years.png")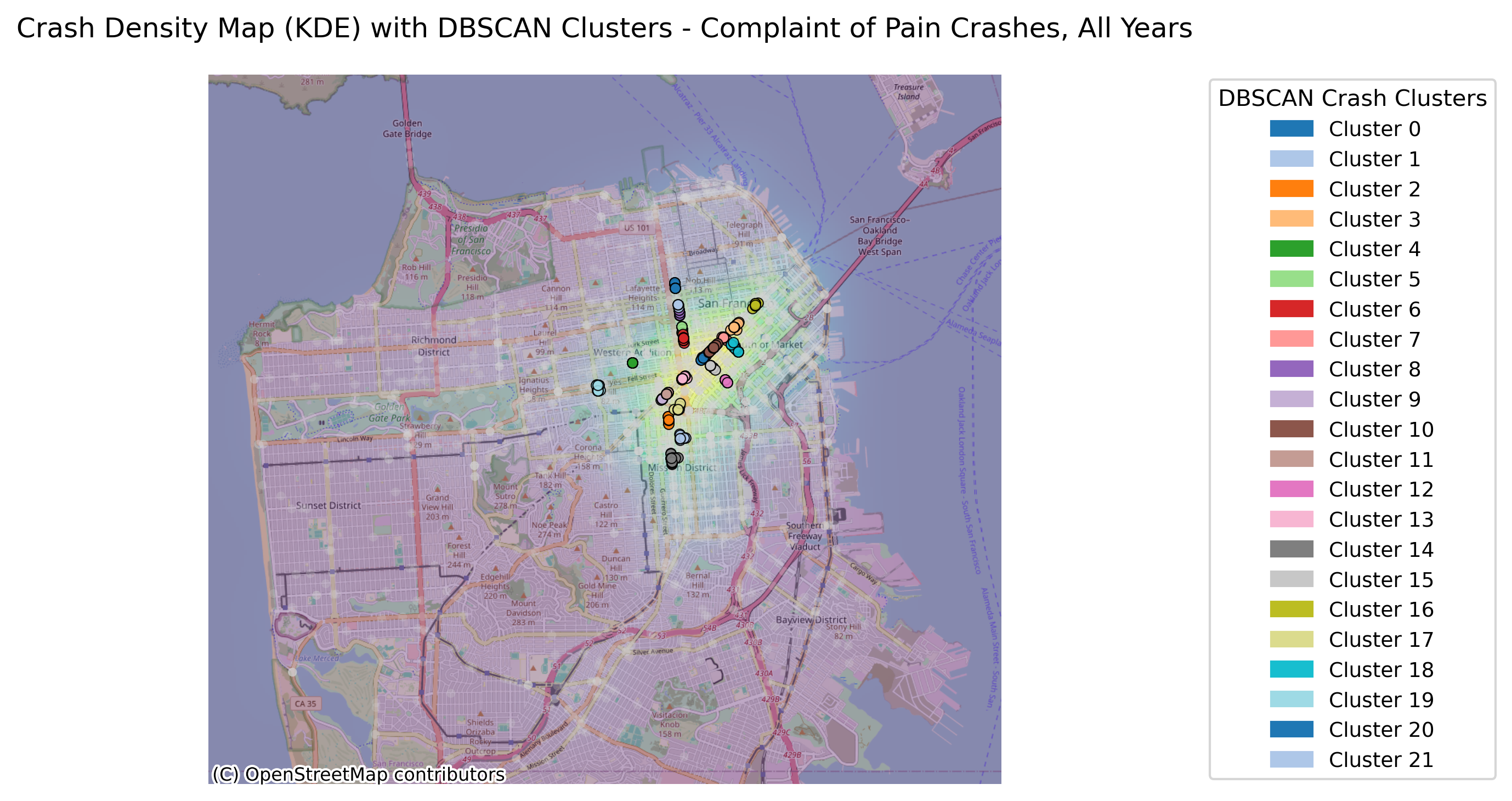
Image(filename = "figures/top_roads_Complaint_of_Pain_Crashes,_All_Years.png")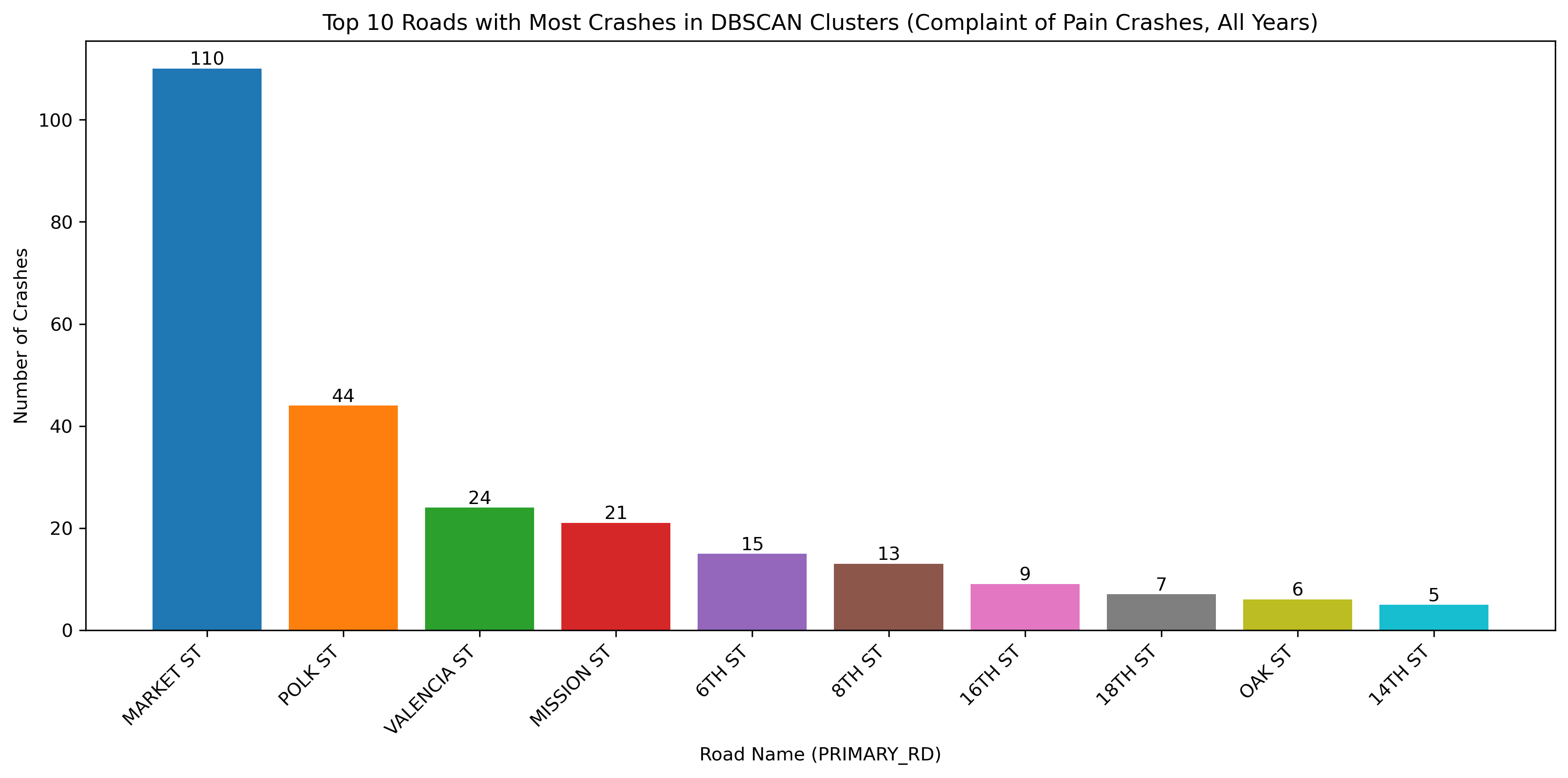
Street Trends¶
The above graphs confirm a startling number of crashes densly clustered on Market Street. However, on January 29, 2020, Market Street was closed to motor vehicles, outside of emergency services and buses. We can see this difference in the two images below. One is from before January 29, 2020, and the other is from after this point.

This is a picture of Market Street from before the vehicle ban. As shown in the photo, we see vehicles sharing space with bicyclists. These interactions increase the probablility of a crash.

This is a picture of Market Street from after the vehicle ban. Less interaction between cars and bikes mean less chances of collision.
The change means that interactions between cars and bikes are now almost zero, except for traffic crossing the street perpendicularly. When we filter out crashes that occured after that date, we see the following.
Image(filename = "figures/crash_clusters_Fatal_Crashes,_After_2020-01-29.png")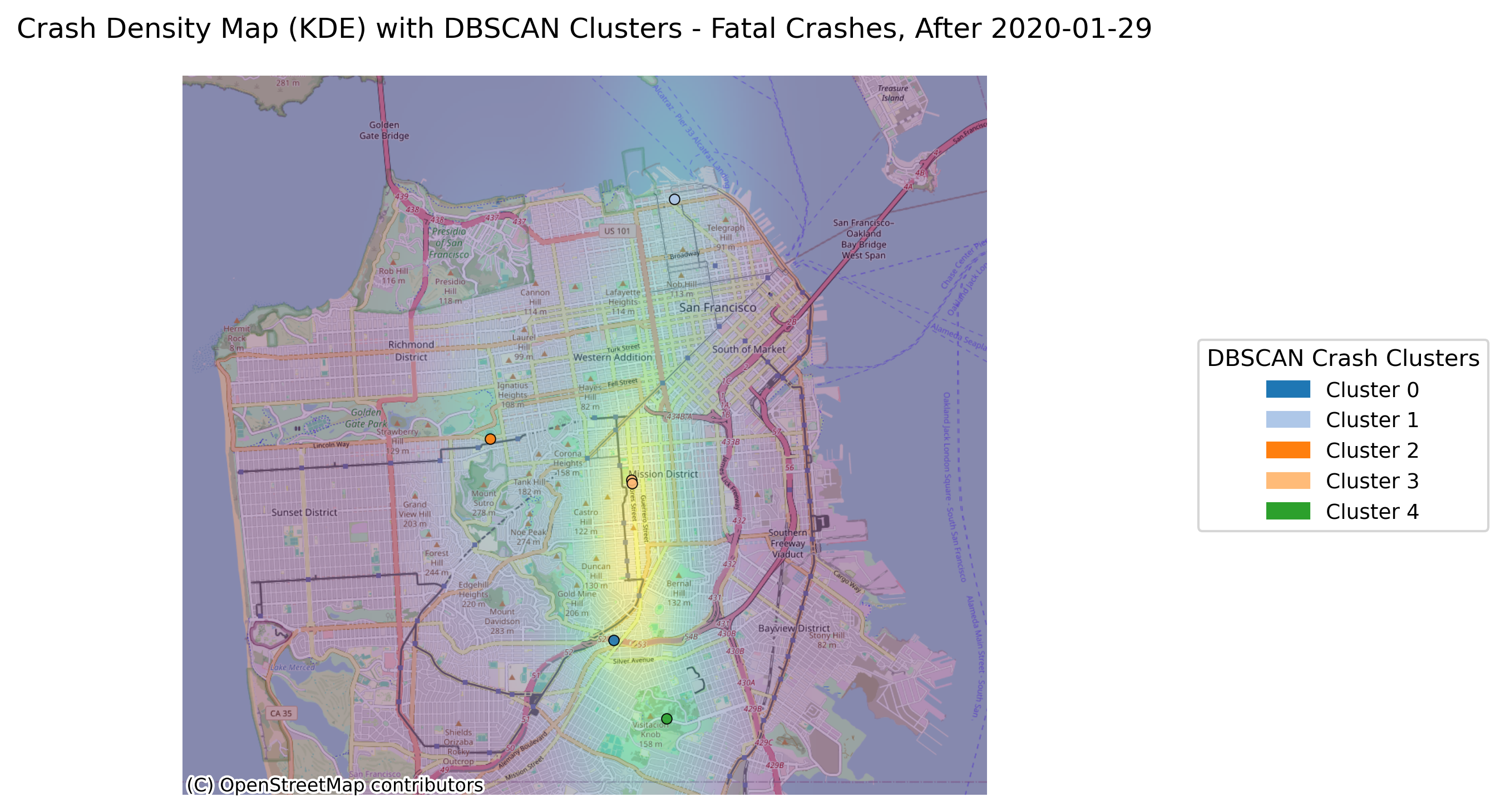
Image(filename = "figures/top_roads_Fatal_Crashes,_After_2020-01-29.png")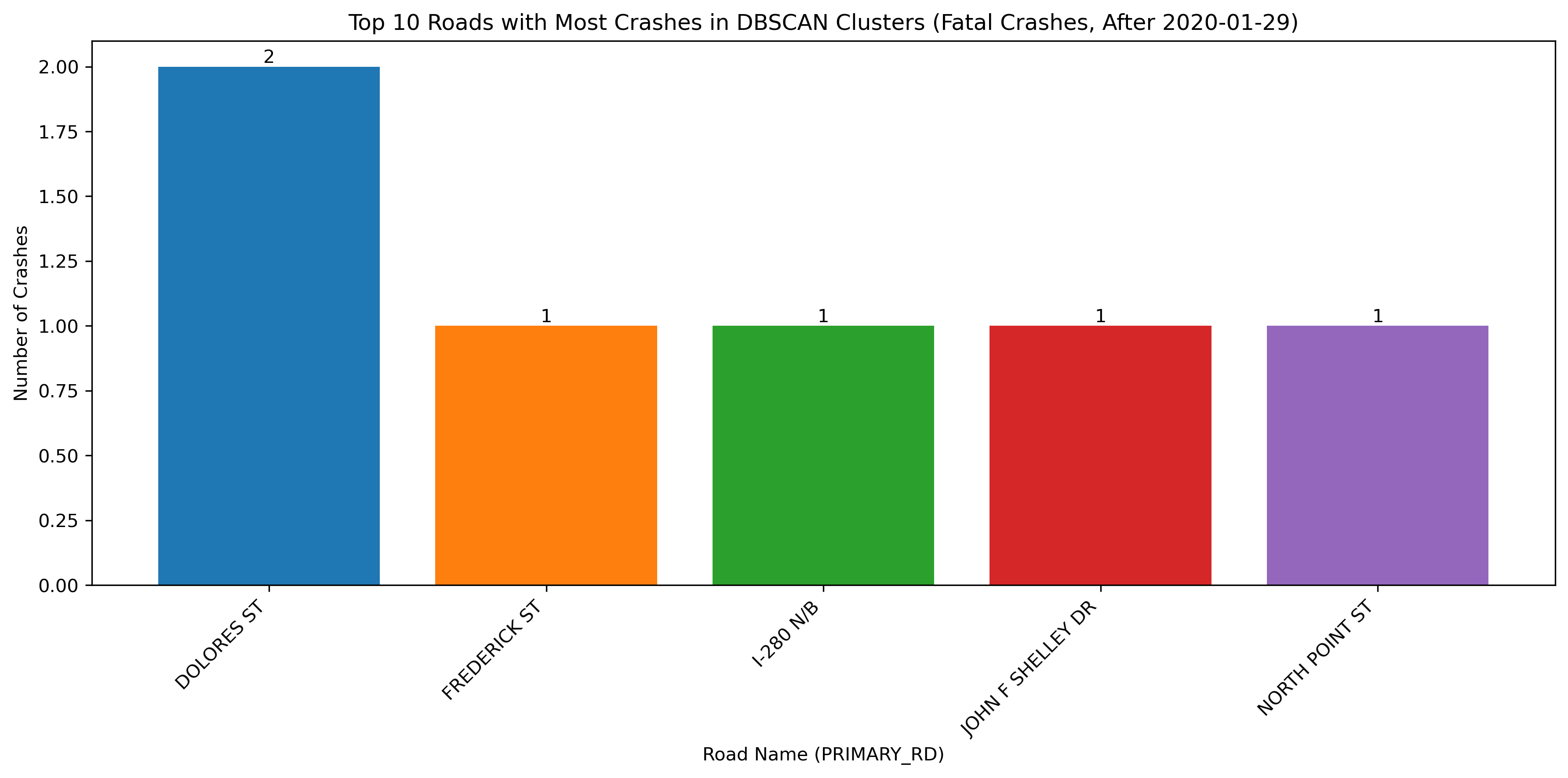
Now that the time span has been decreased, there are even fewer crashes and the minimum number of clusters for the analysis was again set to 1 in order to visualize where the fatal crashes occured.
Image(filename = "figures/crash_clusters_Severe_Crashes,_After_2020-01-29.png")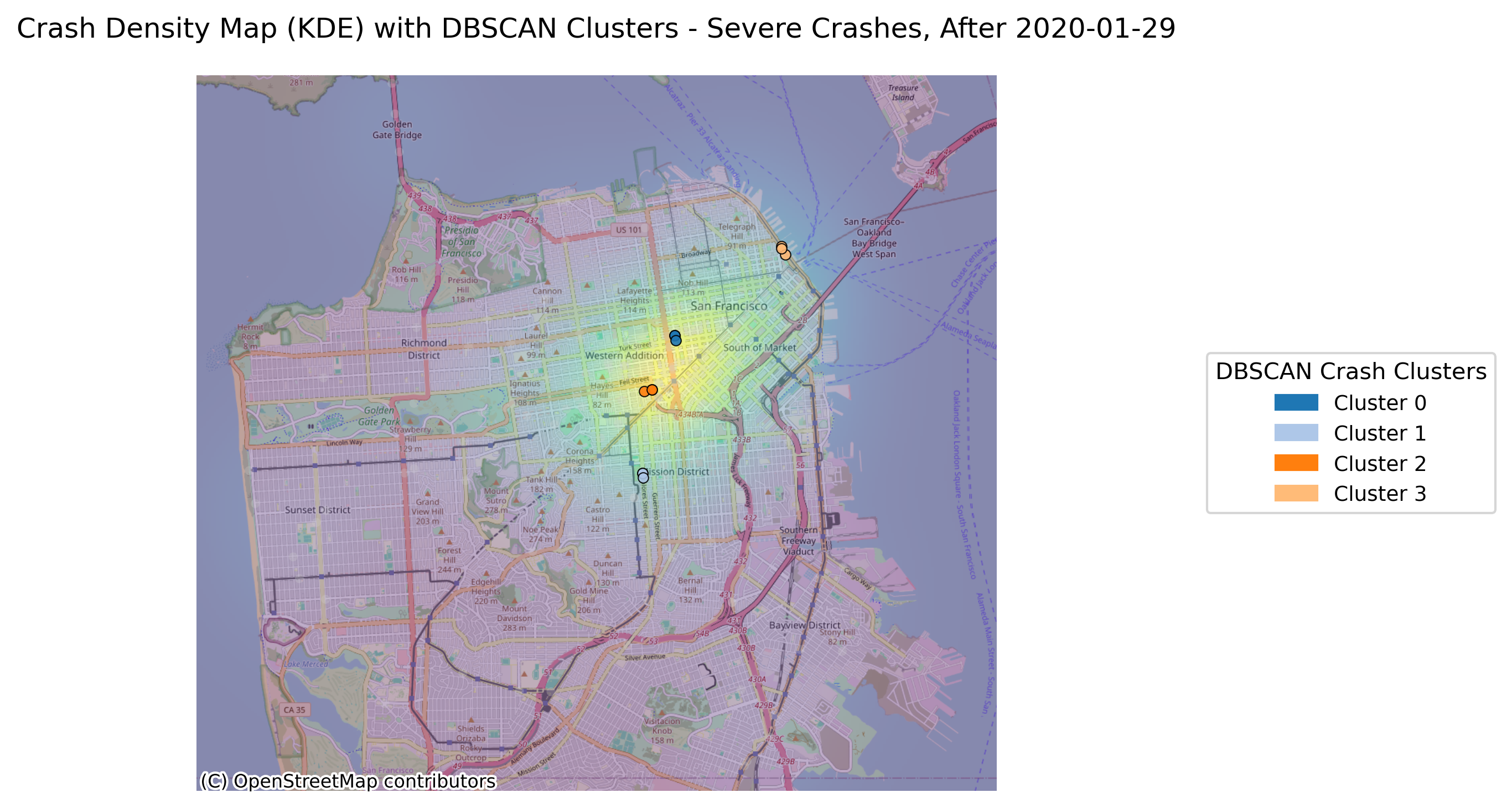
Image(filename = "figures/top_roads_Severe_Crashes,_After_2020-01-29.png")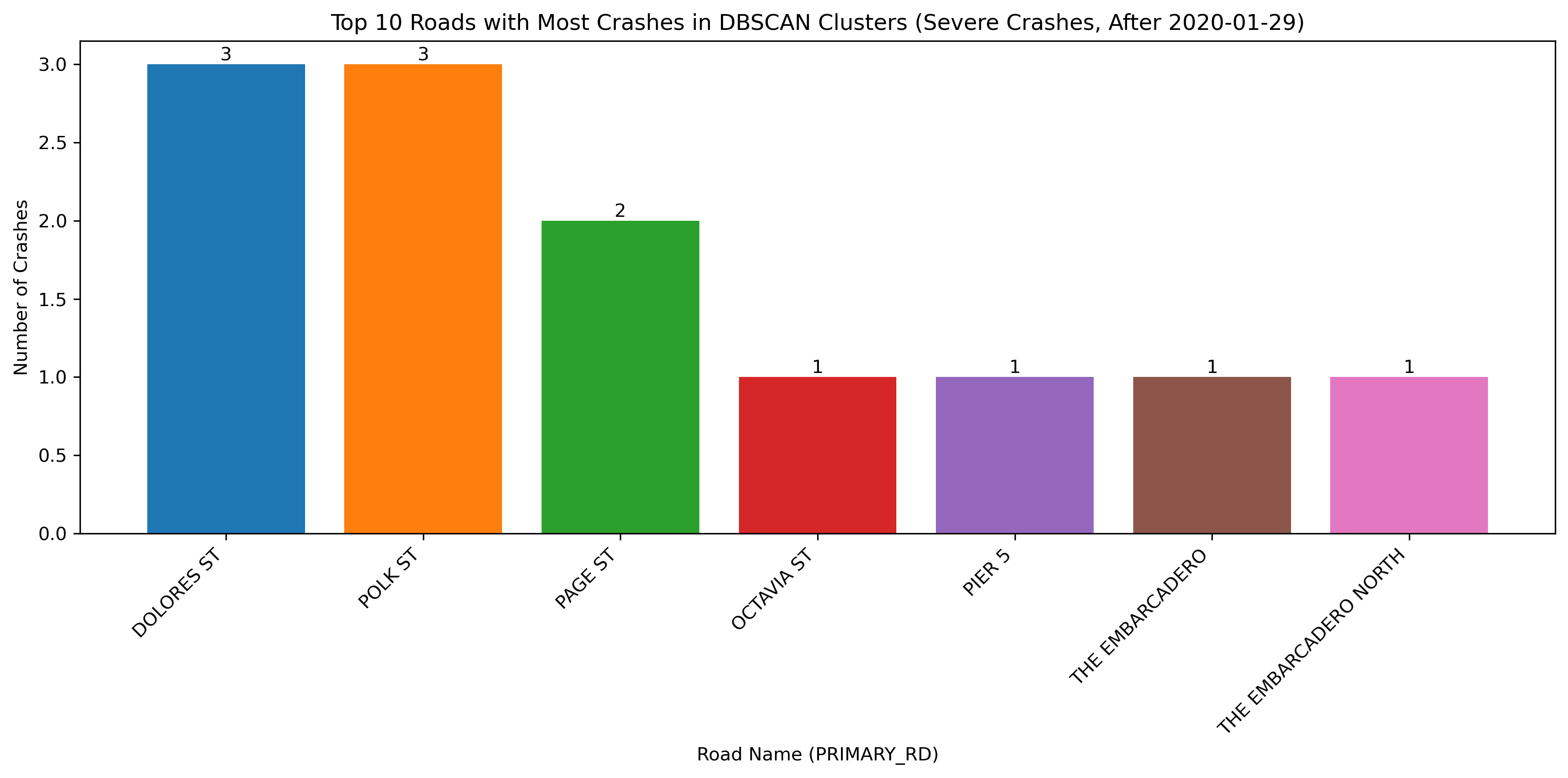
Image(filename = "figures/crash_clusters_Injury_Crashes,_After_2020-01-29.png")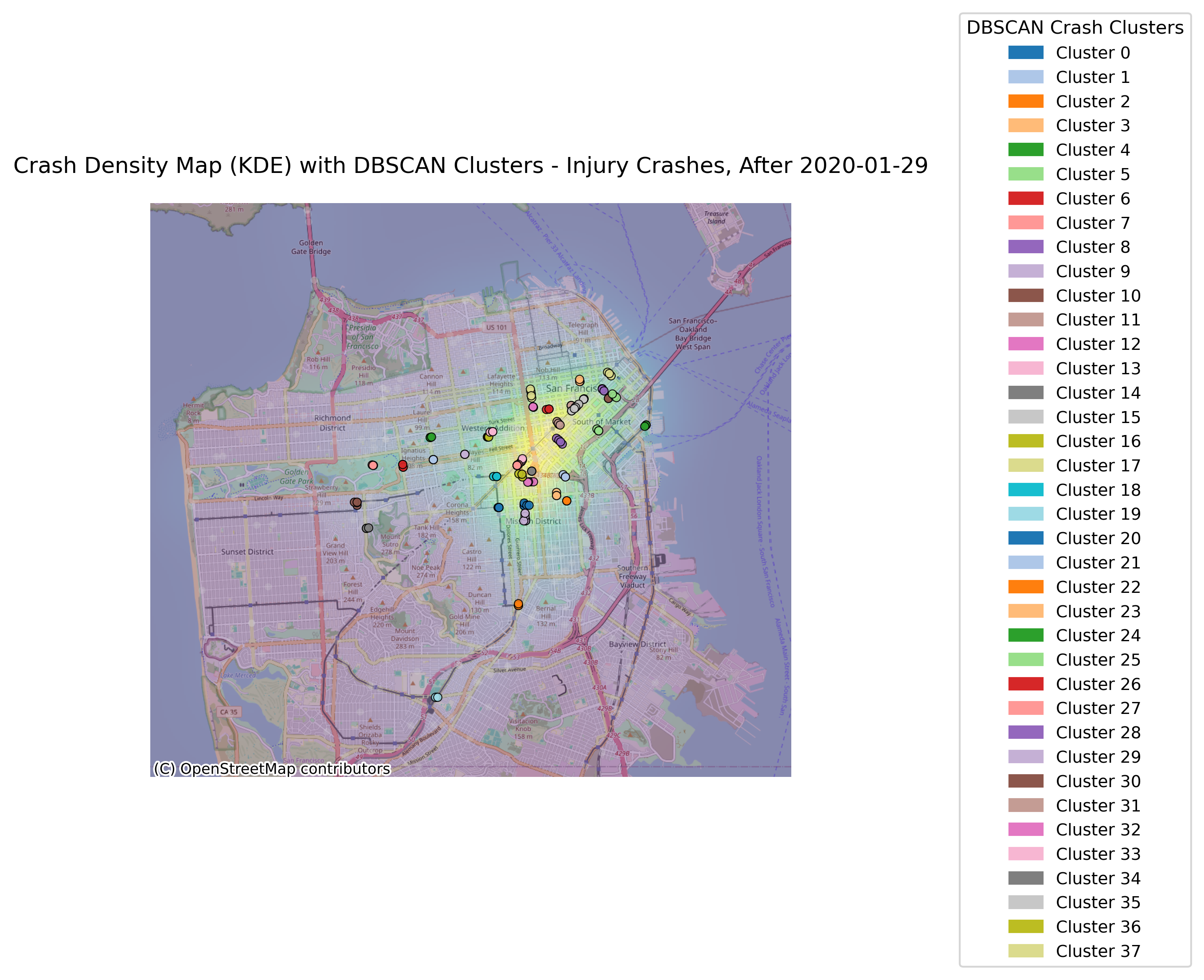
Image(filename = "figures/top_roads_Injury_Crashes,_After_2020-01-29.png")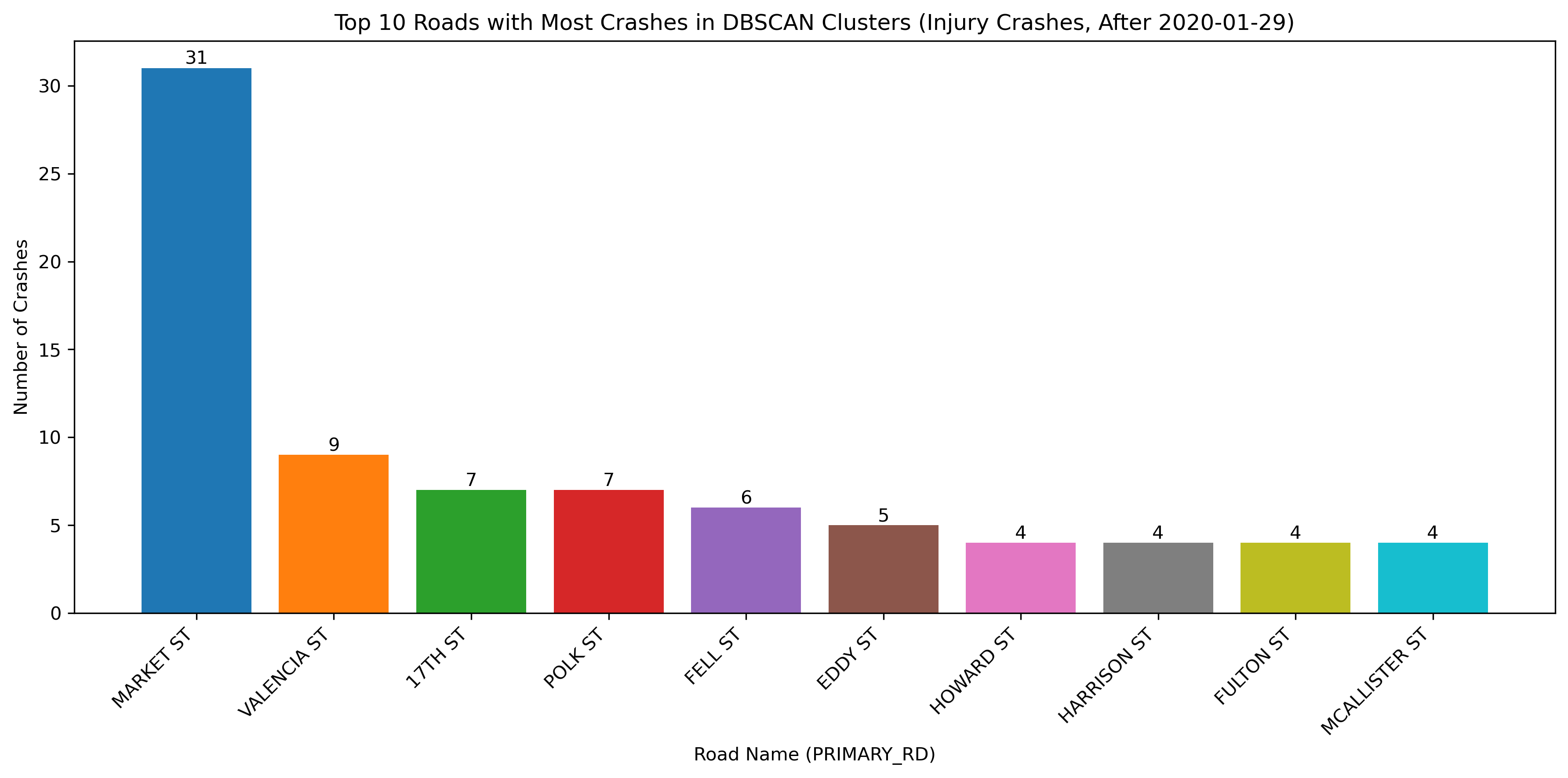
Image(filename = "figures/crash_clusters_Complaint_of_Pain_Crashes,_After_2020-01-29.png")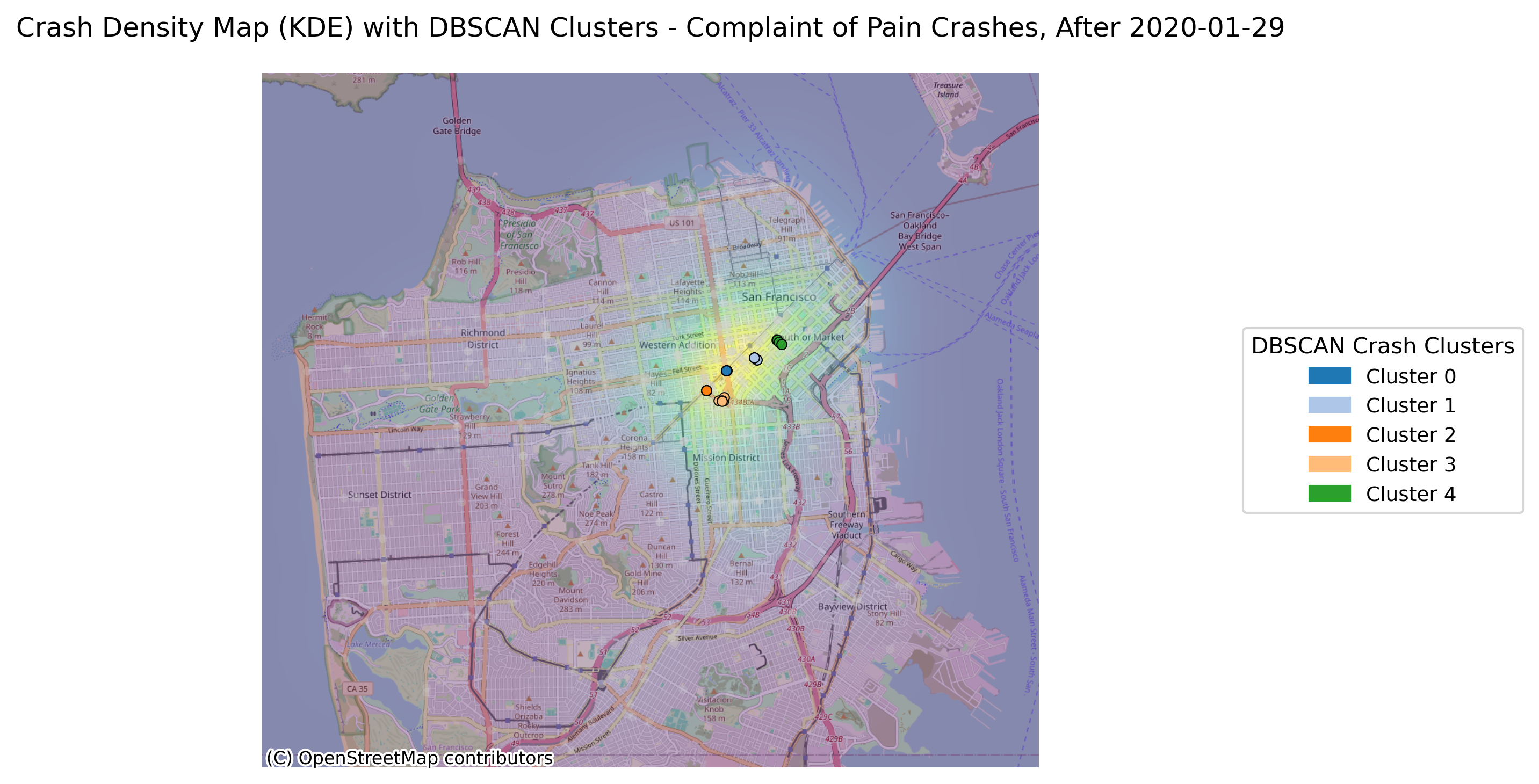
Image(filename = "figures/top_roads_Complaint_of_Pain_Crashes,_After_2020-01-29.png")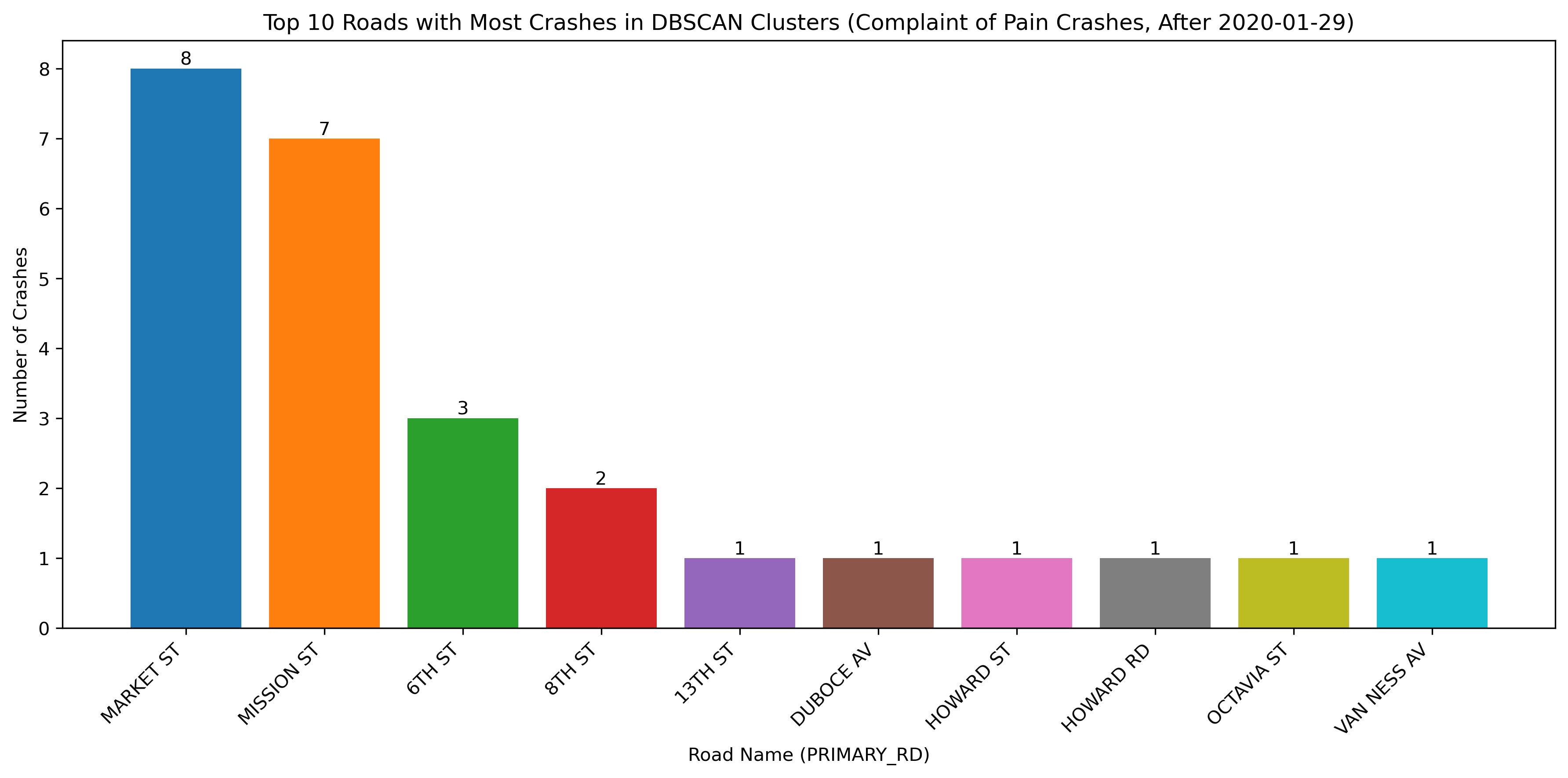
With the change in vehicle allowance on Market Street, it is not surprising that Market Street no longer consistently comes up as a road with an exorbinant amount of crashes. Interestingly, it still appears to have many clustered crashes resulting in visible injuries. However, more consistently, we see roads such as Dolores Street, Frederick Street, and Polk Street. Even when looking at the data over all years, we can see that these three streets appear to have more crashes and are consistently flagged.
This indicates that there may be infrastructure characteristics that influence the propensity of bicycle crashes on these roads.

The above image shows Dolores Street, which does not have bike lanes or any protective considerations for those who may use different modes of travel such as bicycles, scooters, or skateboards. Dolores Street shows high levels of bicyclist fatalities and severe injuries since 2020. This trend may justify the need for greater bicycle safety considerations such as bike lanes.

Similar to Dolores Street, Frederick Street also does not have bike lanes. Adding these protections and possibly other safety measures such as speed calming measures, more robust infrastructure, or greater signage could help decrease instances of bike collisions.

Polk Street has better bicycle infrastructure; however, it was inconsistent. Some of the bike lane has vertical infrastructure, while other places do not. Further, there are many access points along Polk, such as perpendicular streets and driveways. These are generally unsafe conditions as they create multiple possible interaction points where crashes may occur. Special design considerations should be made that could protect cyclists. Making this street a slow street could be the best way to ensure that any collision that does happen is of the lowest severity.
Photo Credit: Google Maps
Bike Crash Severity Modelling for San Francisco¶
Introduction¶
In this section we develop models guided by insights from the exploratory data analysis. Our goal is to identify the factors that most strongly predict cyclist injury severity in San Francisco. This differs from studies such as Scarano et al. (2023), which use national datasets and more advanced modeling frameworks; our work applies similar count and severity models to San Francisco’s TIMS bicycle crash data. This is useful because a city-level analysis captures local patterns and street conditions that broader national studies cannot reflect. Although TIMS data are pre-processed and standardized, additional cleaning and filtering were required to obtain a consistent set of San Francisco bicycle crashes suitable for modeling.
Crash Severity Categories¶
The data considers four crash severities. The outcome of this kind of statistical modelling is highly dependent on the proportion of data available for each crash severity. In our dataset, the distribution of crash severities is as follows: Fatal (0.5%), Severe Injury (9.5%), Other Visible Injury (44.4%), and Complaint of Pain (45.7%). Given the low proportion of fatal crashes, we combine Fatal and Severe Injury into a single category called “Severe Injury” and combined the other categories into “Other Injury”. This results in two categories: Killed or Severely Injured (10%) and Other Injury (90%).
# Display crash severity summary table
import pandas as pd
severity_table = pd.read_csv("figures/crash_severity_summary.csv")
display(
severity_table.style.hide(axis="index").format({
"Number of events": "{:,}",
"Percent of total": "{:.1f}%"
})
)
# Display KSI crash severity summary table
ksi_table = pd.read_csv("figures/KSI_crash_severity_summary.csv")
display(
ksi_table.style.hide(axis="index").format({
"Number of events": "{:,}",
"Percent of total": "{:.1f}%"
})
)
Crash Severity Models¶
Three classification models: 1) multinomial logit model, 2) random forest, and 3) XGBoost, were used to predict the severity of cyclist injuries in crashes. Reference was made to the research by Scarano et al. (2023). The models estimate the probability of Killed or Severely Injured (KSI) or Other injury based on various predictor variables such as road conditions, weather, time of day, cyclist demographics, etc. To determine which parameters to use in the models, we looked at the different variables and removed variables which are nearly constant (low variance).
Since the number of observations in the “Killed and Severely Injured (KSI)” category is very low compared to the “Other injury” category, for each of the models, we applied some form of class balancing such that the loss allocation across the different categories was approximately equal. The balancing scheme was chosen in a way that maximized the precision (PR) AUC value of each model.
Additionally, in order to determine the best model, we compared their performance using metrics such as accuracy, precision, recall, and F1-score. The model with the highest performance metrics was selected as the best model for predicting severity in San Francisco bike crashes.
Multinomial Logit Model¶
We trained a class-balanced logistic regression using an 80-20 test-train split. The random seed of the split was fixed to ensure reproducibility.
Random Forest Model¶
We trained a class-balanced random forest model using the same 80-20 test-train split and random seed as the logistic regression model. We tried a small set of hyperparameter configurations (varying tree countand depth) and found that PR AUC plateaued with negligible gains. For this reason, we kept a simple, class-balanced RF with fixed hyperparameters.
XGBoost Model¶
We fit an XGBoost classifier with class imbalance handled using scale_pos_weight, using the same 80/20 stratified split and random seed. A quick trial of different tree counts, depths, and learning rates showed PR AUC changes were negligible, so we kept a simple, class-balanced XGBoost configuration with fixed hyperparameters. Additionally, we found that a scale_pos_weight of 0.5 times the weight that balances the classes maximized PR AUC.
# Displaying model summary
import pandas as pd
summary = pd.read_csv("figures/model_summary.csv")
# Keep numeric cols numeric; fill blanks only in the text column
num_cols = ["ROC AUC", "PR AUC", "Precision", "Recall", "F1-score"]
summary[num_cols] = summary[num_cols].apply(pd.to_numeric, errors="coerce")
summary["Model"] = summary["Model"].fillna("")
display(
summary.style.hide(axis="index").format(
formatter={c: "{:.3f}" for c in num_cols},
na_rep="" # show blanks instead of NaN
)
)
Selecting the Best Crash Severity Model¶
Based on the performance metrics, we selected the Random Forest model as the best model since it has the best overall balance. This model has the top ROC AUC (0.620) and the highest KSI F1 and KSI recall values among the three models trained. XGBoost nas a slightly better PR AUC value than Random Forest (0.168 vs 0.156) however, it has much a lower KSI recall and F1 score. It also has the best model for predicting crash severity in San Francisco bike crashes.
The Random Forest model was be used for further analysis and interpretation using SHAP (SHapley Additive exPlanations) to determine the most influential factors in the crash severity model Lundberg & Lee (2017).
SHAP Analysis of the Random Forest Model¶
SHAP values were calculated for the Random Forest model to interpret the influence of each feature on the model’s predictions. The SHAP summary plot shows the impact of each feature on the model output, with features ranked by their importance. The color of the points indicates the value of the feature (red for high values such as 1 for categorical features, blue for low values such as 0 for categorical features), and the position on the x-axis indicates the effect on the prediction (positive or negative impact on KSI probability). Since the primary and secondary road featires were dominating the SHAP plots, we separated them from the other features to better visualize the impact of the other features. For both the road and non-road features SHAP analysis, we created two plots, the SHAP beeswarm plot and the SHAP bar plot. The different categories were interpreted with reference to the TIMS SWITRS data codebook UC Berkeley Safe Transportation Research and Education Center (n.d.).
SHAP Analysis for Road Features¶
From the SHAP analysis of features relating to the road on which the crash occured i.e., “Primary_RD” and “Secondary_RD”, we can see from the SHAP beeswarm and bar plots that some roads have a higher likelihood of KSI crashes. For example, crashes on Bayshore Boulevard, Balboa Street and Hill Street have a higher likelihood of being KSI crashes. On the other hand, crashs on Townsend Street, 18th Street adn California Street have a lower likelihood of being KSI crashes.
Image(filename = "figures/nonroad_shap_beeswarm.png")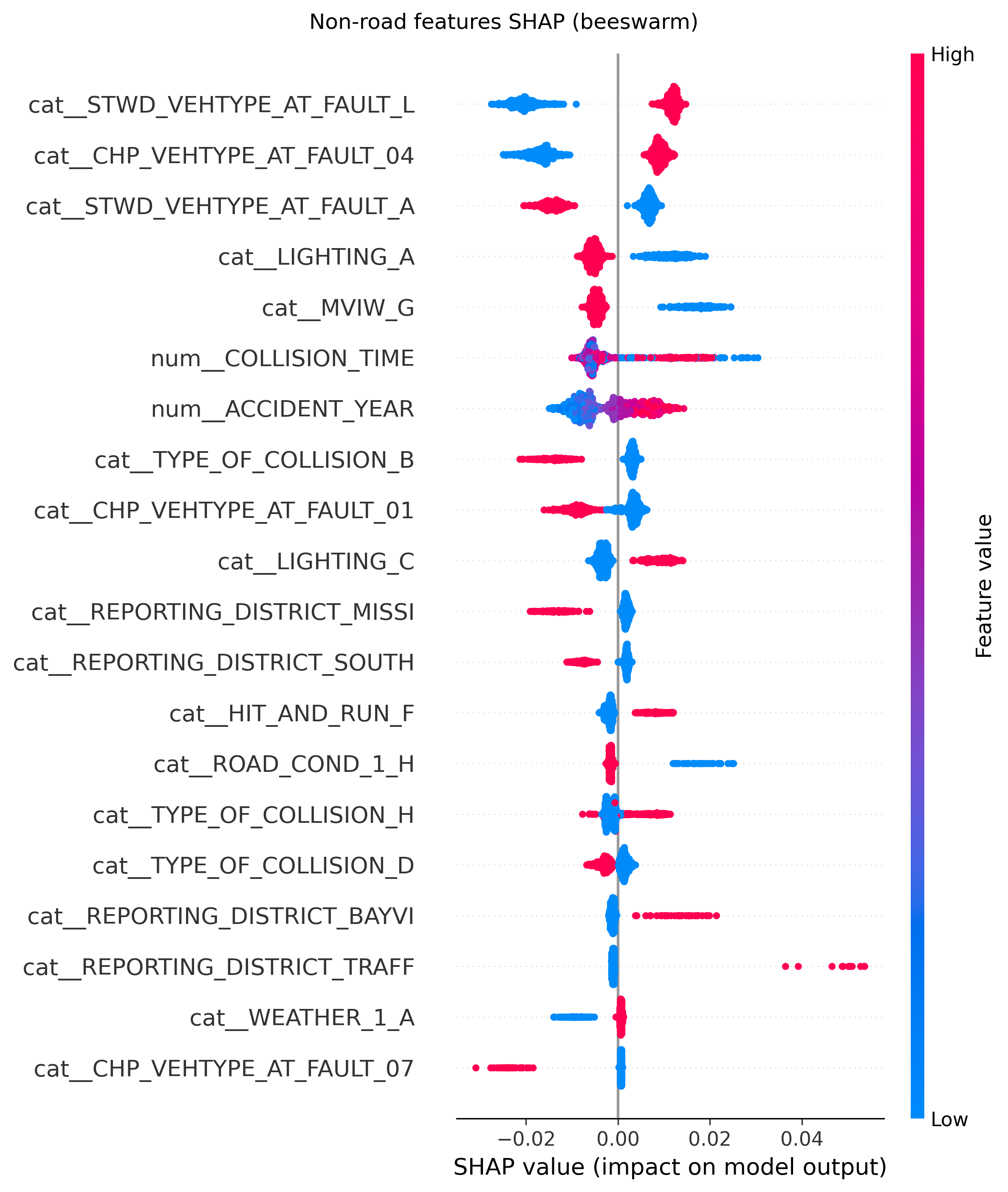
Image(filename = "figures/nonroad_effects_SHAP_bar.png")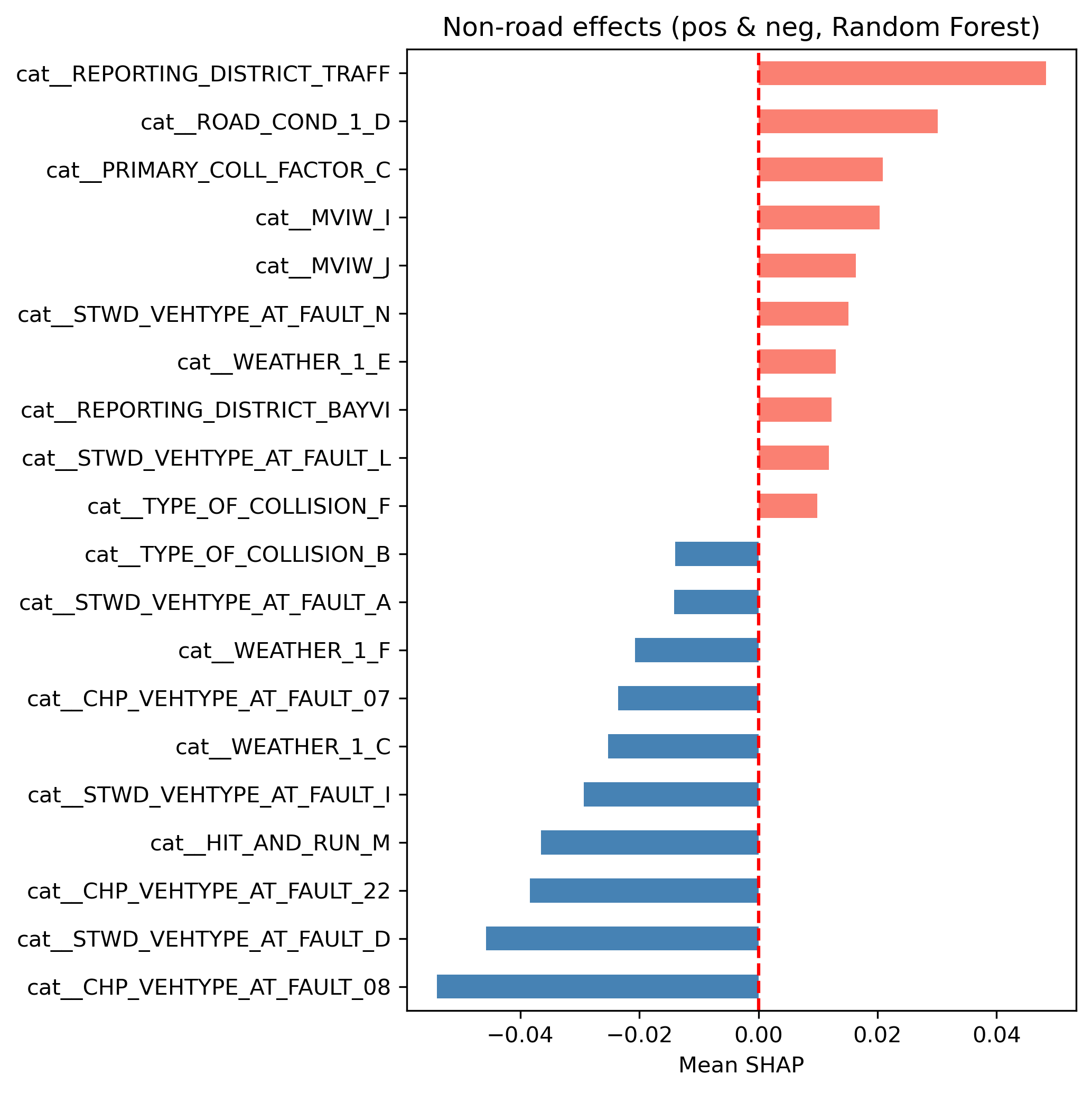
SHAP Analysis for Non-Road Features¶
From the SHAP analysis of features not relating to the road on which the crash occured such as vehicle type at fault, lighting, type of collision, reporting district, collision type, accident year and weather, we can see from the SHAP beeswarm and bar plots that some categories or values have a higher likelihood of KSI crashes. For example, crashes from the traffic reporting district, those on road_condition_1_ D (construction or repair zone), those involving primary_collision_factor_C (other than driver), type_of_collision_F (overturned) and stwd_vehtype_at_fault_L (bicycle) have a higher likelihood of being KSI crashes. On the other hand, crashes where the vehicle type at fault is not the bicycle (is a bus, minivan, truck or sports utility vehicle), the weather is rainy (weather_1_C) or type of collision is a sideswipe(type_of_collision_B) have have a lower likelihood of being KSI crashes.
Image(filename = "figures/nonroad_shap_beeswarm.png")Image(filename = "figures/nonroad_effects_SHAP_bar.png")Major Observations from the Modelling¶
The Random Forest model outperformed the other two models in predicting crash severity in San Francisco bike crashes, especially in identifying KSI (Killed or Severely Injured) crashes. The SHAP analysis revealed that certain roads and crash characteristics significantly influence the likelihood of severe injuries.
As was observed in the clustering analysis, specific roads such as Dolores Street and Bayshore Boulevard are associated with higher severity crashes. These associations were confirmed by the SHAP beeswarm plot for road features, which showed that crashes on these roads have a higher likelihood of being KSI crashes (positive SHAP value).
Additionally, non-road features such as vehicle type at fault, lighting conditions, and type of collision also play a significant role in determining crash severity. Specifically, it was found that crashes in construction or repair zones, those involving a primary collision factor that is not the driver, crashes involving overturning and crashes where the cyclist was at fault have a higher likelihood of being KSI crashes.
These insights, together with what was observed in the EDA and Clustering Analyses, can inform targeted interventions to further improve cyclist safety in San Francisco.
Author Contributions¶
Reily Fairchild: Did the initial set up of the notebook, setting up the environment, makefile, tools, and myst files. Collaborated with Aditya on EDA, and then individually set that section in a strong narrative framing and consistent graph visuals.
Jordan Collins: Did the spatial analysis, Google Maps assessment, and review of files near the end of the project. Made sure to include tests, modularize functions, and create a clean notebook.
Aditya Mangalampalli: Worked on the packaging of our utility package
toolsby adding unit tests, helped contribute to theMakefile, set up themystmdand it’s respective Github Pages hosting, added appropriate licensing, populated theREADMEwith important information about the project, and collaborated with Reily on EDA.Atiila Joselyn Birah Kharobo: Did the modelling section of the project which included data cleaning, model selection, training and evaluation. Additionally, did SHAP analysis to interpret the model results and included visualizations and tests to support the findings.
- Safe Transportation Research and Education Center (SafeTREC). (2024). Transportation Injury Mapping System (TIMS). University of California, Berkeley. https://tims.berkeley.edu
- California Highway Patrol. (2024). Statewide Integrated Traffic Records System (SWITRS). https://www.chp.ca.gov/programs-services/services-information/switrs
- pandas development team, T. (2023). pandas: Powerful data structures for data analysis in Python. https://pandas.pydata.org
- Harris, C. R., & others. (2020). NumPy: The fundamental package for scientific computing with Python. In Nature (Vol. 585, pp. 357–362).
- Silverman, B. W. (1986). Density Estimation for Statistics and Data Analysis. Chapman.
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining.
- Jordahl, K., & others. (2023). GeoPandas: Python tools for geographic data. https://geopandas.org
- Scarano, A., Rella Riccardi, M., Mauriello, F., D’Agostino, C., Pasquino, N., & Montella, A. (2023). Injury severity prediction of cyclist crashes using random forests and random parameters logit models. Accident Analysis & Prevention, 192, 107275. 10.1016/j.aap.2023.107275
- Lundberg, S. M., & Lee, S.-I. (2017). SHAP: A Unified Approach to Interpreting Model Predictions. https://shap.readthedocs.io/en/latest/
- UC Berkeley Safe Transportation Research and Education Center. (n.d.). Traffic Injury Mapping System (TIMS): SWITRS Codebook. https://tims.berkeley.edu/help/SWITRS.php#Codebook